蓄水池算法
在未知数据长度的情况下,从长度为n的数组中随机抽取k个数,但是n是未知的,不知道何时结束。
特例就是在数据流中随机抽取一个数,使得抽取每个数的概率均等
均匀不带权取样:
场景
无限数据流中随机取一条数据,使得取出每条数据的概率均等。比如实时文件流、监控实时数据。在监控实时数据里,可能一天产生5000w条数据,但是只想均匀取出1000w条存储。
假设sample数组表示抽样结果,最开始流入k个元素一次放入sample[0,k-1]; 对于后面的元素,假设当前流入的是第 i 个元素(i > k),则以 $\frac{k}{i}$ 的概率留下该元素,即当产生[1,i] 的随机数小于等于 k 的时候,就替换掉随机数位置的元素。
下面是Python代码:
import random import copy def reservoir_sample(data, k): sample = [0]*k for i, element in enumerate(data): if i < k: sample[i] = element else: # random.randint() 是闭区间! pos = random.randint(0, i) if pos < k: # pos < k, replace elem with data[i], or not sample[pos] = element return sample
测试用例:
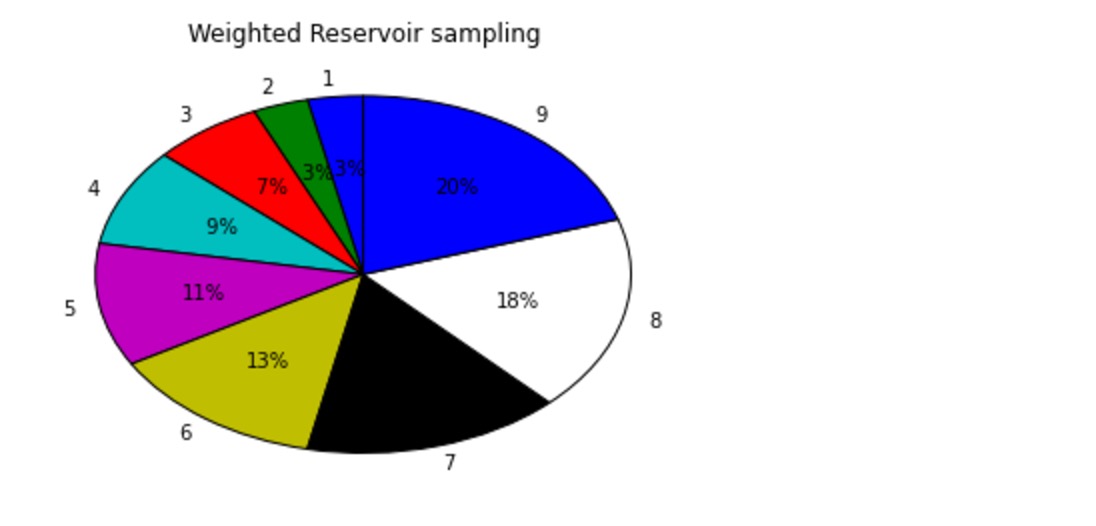
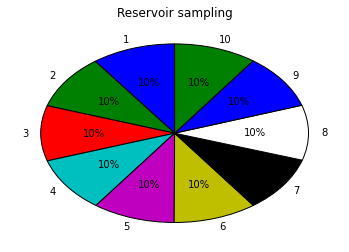
import collections data = [1,2,3,4,5,6,7,8,9,10] k = 1 n = 100000 counter = {} results = [] for i in range(n): res = reservoir_sample(data, k) # res = reservior_sampling(data, k) # res = reservoirSampling(data, k) results.extend(res) t = collections.Counter(results) t import matplotlib.pyplot as plt %matplotlib inline labels = [] sizes = [] for k, v in t.items(): labels.append(k) sizes.append(v) patches, l_text, p_text = plt.pie(sizes, labels=labels, labeldistance=1.1, autopct='%2.0f%%', shadow=False, startangle=90, pctdistance=0.6) plt.title("Reservoir sampling") plt.show()
蓄水池算法证明:
要想理解这个问题,我们考虑最终被留在sample里的元素为什么或被留下,模拟这个过程就知道,即当他被加入的时候,后续步骤永远不会被替换掉。
假设1~k 个元素中任意一个元素能够存在,说明后续流入过程中,该元素都没有被替换,比如第一个位置的元素,那么当第 k+1 个元素来的时候,取不属于第一个位置的k个元素(2~k+1)即可,概率为 $\frac{k}{k+1}$, 后续以此类推,那么通过条件概率计算:
$1 \cdot [\frac{k}{k+1}\cdot \frac{k+1}{k+2} \cdots \frac{k+n-k-1}{k+n-k}] = \frac{k}{n}$
对于k+1~n 个元素中的任意一个元素,最终能够留下来的概率就是在流入的时候被选取留下,并且后续不再被替换,假设当前流入的是第 i (i > k)个元素, 首先要留下该元素的概率是在k个已经留下的元素里面任选一个位置放入该元素,概率是 $\frac{k}{i}$, 要想最后数据流结束的时候这个元素还能被留下来,且概率为 $\frac{k}{n}$,第一种想法就是强行凑出这样一种公式,这是高中数学里面很常见的一个连乘分子分母相消例子。那么条件概率计算就是:
$\frac{k}{i} \cdot [\frac{i}{i+1} \cdot \frac{i+1}{i+2} \cdots \frac{n-1}{n}] = \frac{k}{n}$
第二种想法就是,后续的数据流入过程中,每流入一个新元素,那么被留下表示事件$A$,被留下的意思是替换其他位置的元素或者不进行任何替换就表示事件,不被留下表示事件 $\bar{A}$, 即概率是 $p(\bar{A}) = \frac{1}{i+1}$, 那么$p(A)=\frac{i}{i+1}$. 以此类推。
不均匀带权取样
现在假设每一个元素都有一个权重,随机抽取K个元素,每一个元素被选中的概率和元素自身权重成正比。
场景
推荐系统中,推荐的结果通常是一个数组,而且每个结果概率不一样,第一种是排序取最大,第二种就是引入随机推荐,按照概率随机取一个或多个进行推荐。
序列sequence中的每个元素i都由 sequence[i].value 和 sequence[i].weight构成。现在取k个元素,每个元素抽取的概率为 $sequence[i].weight$.
假设sample数组表示抽样结果,最开始流入k个元素一次放入sample[0,k-1]; 对于后面的元素,假设当前流入的是第 i 个元素(i > k),则以 $\frac{sequence[i].weight}{\sum_k^{i}{sequence[k].weight}} \cdot k$ 的概率留下该元素. 如果元素留下,替换谁呢?这里的Trick就是随机均匀的从sample从取一个替换掉,这是可以保证最后元素留下来的概率和权重成正比。
对于取k=1 的情况,比较好理解,和均匀取样是一样的,选中以后就必须被替换.
$$
p = \frac{sequence[i].weight}{\sum_k^{i}{sequence[k].weight}} \cdot [(1-\frac{sequence[i+1].weight}{\sum_k^{i+1}{sequence[k].weight}}) \cdot (1-\frac{sequence[i+2].weight}{\sum_k^{i+2}{sequence[k].weight}}) \cdots (1- \frac{sequence[n].weight}{\sum_k^{n}{sequence[k].weight}})]
= \frac{sequence[i].weight}{\sum_k^{i}{sequence[k].weight}} \cdot [(\frac{\sum_k^{i}{sequence[k].weight}}{\sum_k^{i+1}{sequence[k].weight}}) \cdot \frac{\sum_k^{i+1}{sequence[k].weight}}{\sum_k^{i+2}{sequence[k].weight}} \cdots \frac{\sum_k^{n-1}{sequence[k].weight}}{\sum_k^{n}{sequence[k].weight}}]
= \frac{sequence[i].weight}{\sum_k^{n}{sequence[k].weight}}
$$
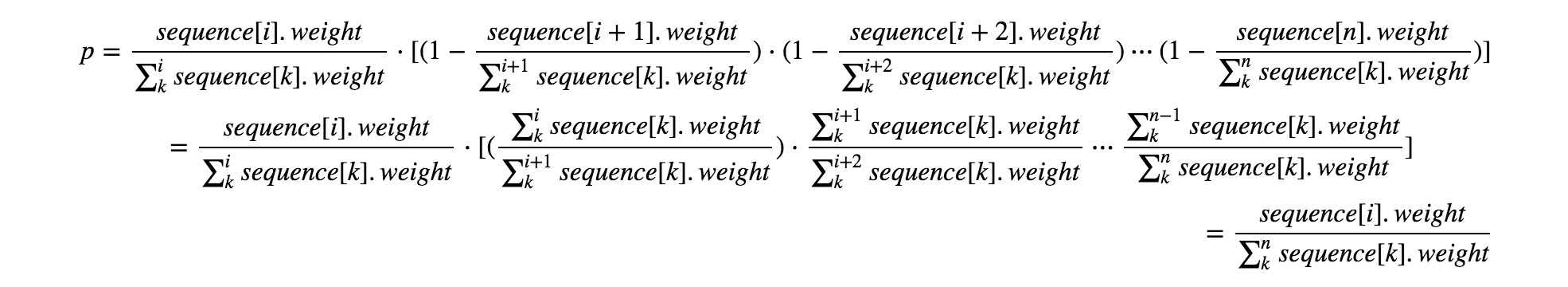
对于取k > 1 的情况,实际上对于小数据集是不成立的,因为假设有两个数,我需要取两个数,那么两个数被取的概率就是1,并不和权重成正比,因此这里公式是一种大数据集合上的近似,对于后续流入的数据,就可以保证是按照权重取的。还是以某个正在流入的数据i来计算他最终被留下来的概率,当前它被留下的概率是 $P = \frac{k*sequence[i].weight}{\sum_k^{i}{sequence[k].weight}}$, 他最终要想被留下来,那么后面的元素i+1 必定有两种情况,第一是元素 i+1 不被选中,概率 $P1 = 1-\frac{k*sequence[i+1].weight}{\sum_k^{i+1}{sequence[k].weight}}$, 第二种情况是 i+1 也被选中,但是不替换第 i 个元素,则 $P2 = \frac{k*sequence[i+1].weight}{\sum_k^{i+1}{sequence[k].weight}} \frac{k-1}{k}$. 那么当第 i+1 个元素流入时,元素 i 被留下概率就是 $P(P1 + P2)$,以此类推,元素i在后续一直被留下来的概率是
$$
P(i) = \frac{k*sequence[i].weight}{\sum_k^{i}{sequence[k].weight}} \cdot [(1-\frac{k*sequence[i+1].weight}{\sum_k^{i+1}{sequence[k].weight}} + \frac{k*sequence[i+1].weight}{\sum_k^{i+1}{sequence[k].weight}} \frac{k-1}{k}) \cdot (1-\frac{k*sequence[i+2].weight}{\sum_k^{i+2}{sequence[k].weight}} + \frac{k*sequence[i+2].weight}{\sum_k^{i+2}{sequence[k].weight}} \frac{k-1}{k}) \cdots (1- \frac{k*sequence[n].weight}{\sum_k^{n}{sequence[k].weight}} + \frac{k*sequence[n].weight}{\sum_k^{n}{sequence[k].weight}} \frac{k-1}{k})]
\
= \frac{k*sequence[i].weight}{\sum_k^{i}{sequence[k].weight}} \cdot [(\frac{\sum_k^{i}{sequence[k].weight}}{\sum_k^{i+1}{sequence[k].weight}}) \cdot \frac{\sum_k^{i+1}{sequence[k].weight}}{\sum_k^{i+2}{sequence[k].weight}} \cdots \frac{\sum_k^{n-1}{sequence[k].weight}}{\sum_k^{n}{sequence[k].weight}}]
\
= \frac{k*sequence[i].weight}{\sum_k^{n}{sequence[k].weight}}
$$

代码如下:
def weighted_reservior_sample(sequence, k): n = len(sequence) if k > n: return sequence wsum = 0 sample = list() for i in range(k): sample.append(sequence[i]['value']) wsum += sequence[i]['weight'] for i in range(k, n): wsum += sequence[i]['weight'] p = k * sequence[i]['weight'] / wsum j = random.random() if j <= p: sample[random.randint(0, k-1)] = sequence[i]['value'] return sample
测试如下:
import collections data = [1,2,3,4,5,6,7,8,9,10] seq = [{'weight': i * 1., 'value': i} for i in range(1, 10)] print(seq) k = 2 n = 1000000 counter = {} results = [] for i in range(n): res = weighted_reservior_sample(seq, k) # res = reservoir_sample(data, k) # res = reservior_sampling(data, k) # res = reservoirSampling(data, k) results.extend(res) t = collections.Counter(results) t