RPC
RPC(Remote Procedure Call)或者RMI(Remote Method Invoke,JDK中)是进程间通讯的高级形式,RPC的技术本质是网络编程,可以采用经典的客户端-服务器模型来实现,而RPC的理念是使得调用另一个进程里的方法就像是调用当前进程的方法一样,从而复用底层网络通讯的代码,让代码编写更加简单,程序员不用关注方法是如何通过网络在另一个进程中执行并返回结果的,就好象这个方法是一个本地方法一样。
协议
RPC可以基于TCP协议实现,也可以基于HTTP协议,甚至通过消息中间件,任何基本的进程间通讯方式都可以实现RPC,因为RPC只是进程间通讯的高级形式,是对进程间通讯的封装而已。从这个角度来说,任何语言都是可以互相实现RPC的。因为就网络模型来讲,是语言无关的,只要双方遵守相同的协议即可。
但是不同语言在方法调用和使用机制上存在不同,所以RPC的编码使用方式就不同。比如Java就采用反射和和多态机制,以及动态代理的模式实现对象的RPC调用。对于Python 这种动态类型的语言,因为是鸭子类型,代理模式实现更加简单,只需要对客户端进行简单的封装就行了,Python对象的方法调用都是动态绑定的。
java 实现的客户端RPC代理
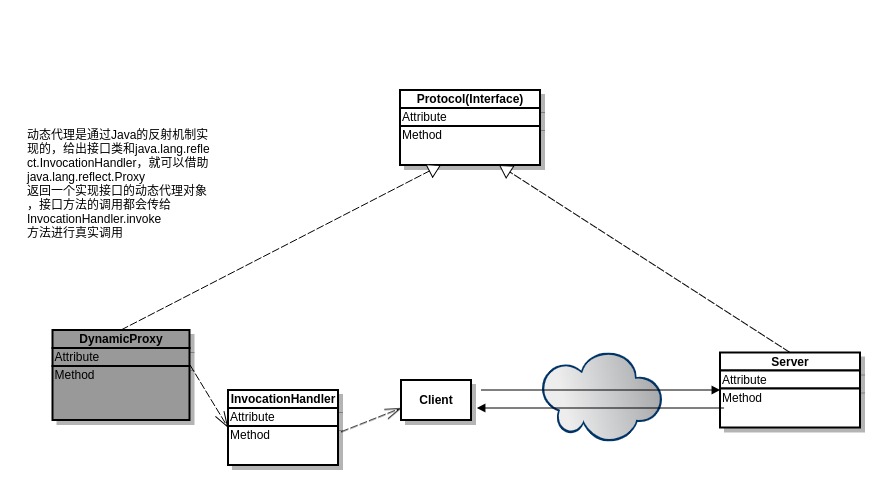
基于动态代理和反射,通过严格的接口继承,Java 可以实现像调用远程对象方法一样调用一个代理接口方法。但是实现起来会麻烦很多。Hadoop 中利用 Java 自己实现了一套序列化框架,就是WritableObject,主要实现对象的编码和解码工作,后续会详细介绍。Java 动态代理实现 RPC 需要用到 java.lang.reflect 包,实现的类图结构如下所示:
public class RPC { // serializable Invocation param for each rpc call /** A method invocation, including the method name and its parameters. */ private static class Invocation implements Writable { private String methodName; private Class[] parameterClasses; private Object[] parameters; public Invocation() { } public Invocation(Method method, Object[] parameters) { this.methodName = method.getName(); this.parameterClasses = method.getParameterTypes(); this.parameters = parameters; } /** The name of the method invoked. */ public String getMethodName() { return methodName; } /** The parameter classes. */ public Class[] getParameterClasses() { return parameterClasses; } /** The parameter instances. */ public Object[] getParameters() { return parameters; } public void readFields(DataInput in) throws IOException { methodName = in.readUTF(); parameters = new Object[in.readInt()]; parameterClasses = new Class[parameters.length]; ObjectWritable objectWritable = new ObjectWritable(); for (int i = 0; i < parameters.length; i++) { parameters[i] = ObjectWritable.readObject(in, objectWritable); parameterClasses[i] = objectWritable.getDeclaredClass(); } } public void write(DataOutput out) throws IOException { out.writeUTF(methodName); out.writeInt(parameterClasses.length); for (int i = 0; i < parameterClasses.length; i++) { ObjectWritable.writeObject(out, parameters[i], parameterClasses[i]); } } public String toString() { StringBuffer buffer = new StringBuffer(); buffer.append(methodName); buffer.append("("); for (int i = 0; i < parameters.length; i++) { if (i != 0) buffer.append(", "); buffer.append(parameters[i]); } buffer.append(")"); return buffer.toString(); } } private static class Invoker implements InvocationHandler { private Client client; private boolean isClosed = false; public Invoker(Class<? extends VersionedProtocol> protocol, InetSocketAddress address, String ticket, SocketFactory factory, int rpcTimeout) throws IOException { // this.remoteId = Client.ConnectionId.getConnectionId(address, protocol, ticket, rpcTimeout); // this.client = CLIENTS.getClient(conf, factory); } public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { ObjectWritable value = (ObjectWritable) client.call(new Invocation(method, args), remoteId); return value.get(); } } public static VersionedProtocol getProxy(Class<? extends VersionedProtocol> protocol, long clientVersion, InetSocketAddress addr, String ticket, SocketFactory factory, int rpcTimeout) throws Exception { VersionedProtocol proxy = (VersionedProtocol) Proxy.newProxyInstance(protocol.getClassLoader(), new Class[] { protocol }, new Invoker(protocol, addr, ticket, factory, rpcTimeout)); // long serverVersion = proxy.getProtocolVersion(protocol.getName(), clientVersion); // if (serverVersion == clientVersion) { // return proxy; // } else { // throw new Exception("version mismatch"); // } return proxy; } public boolean securityAuth(String ticket) { return true; } public static void main(String[] args) { try { PingProtocol pingProto = (PingProtocol) RPC.getProxy(PingProtocol.class, PingProtocol.versionID, null, null, null, 0); NodeID nodeId = new NodeID("localhost", 1); // get name representing the running Java virtual machine. String name = ManagementFactory.getRuntimeMXBean().getName(); System.out.println(name); // get pid String pid = name.split("@")[0]; System.out.println("Pid is:" + pid); NodeContext nodeContext = new NodeContext(pid); pingProto.ping(nodeId, nodeContext); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
python实现的基于json序列化的简易 RPC 代理
借助 Python 的元编程方法,直接通过动态绑定以及 __getattr__ 函数的重写,就可以实现一个RPC客户端代理了,非常简单。不需要像 Java 静态强类型语言一样去规定接口,实现接口。
# jsonrpcclient.py import json class RPCProxy: def __init__(self, connection): self._connection = connection def __getattr__(self, name): def do_rpc(*args, **kwargs): self._connection.send(json.dumps((name, args, kwargs))) result = json.loads(self._connection.recv()) return result return do_rpc >>> from multiprocessing.connection import Client >>> c = Client(('localhost', 17000), authkey=b'peekaboo') >>> proxy = RPCProxy(c) >>> proxy.add(2, 3) 5 >>> proxy.sub(2, 3) -1
服务器端
# jsonrpcserver.py import json class RPCHandler: def __init__(self): self._functions = { } def register_function(self, func): self._functions[func.__name__] = func def handle_connection(self, connection): try: while True: # Receive a message func_name, args, kwargs = json.loads(connection.recv()) # Run the RPC and send a response try: r = self._functions[func_name](*args,**kwargs) connection.send(json.dumps(r)) except Exception as e: connection.send(json.dumps(str(e))) except EOFError: pass from multiprocessing.connection import Listener from threading import Thread def rpc_server(handler, address, authkey): sock = Listener(address, authkey=authkey) while True: client = sock.accept() t = Thread(target=handler.handle_connection, args=(client,)) t.daemon = True t.start() # Some remote functions def add(x, y): return x + y def sub(x, y): return x - y # Register with a handler handler = RPCHandler() handler.register_function(add) handler.register_function(sub) # Run the server rpc_server(handler, ('localhost', 17000), authkey=b'peekaboo')
协议除了接口方法外,还要规定协议头,有时候为了安全,还需要引入连接的安全认证,实现 secure RPC. 比如在每个连接建立以后需要检查当前连接的合法性,进行握手和协商版本等,检查合法以后,该连接才能真正开始传输RPC调用。
序列化
序列化是RPC的重要部分,因为任何语言都有数据类型,虽然Python 是动态类型,但是也隐含着使用某个数据是什么类型的以方便使用。方法调用的方法名,参数对象以及返回对象等都得通过网络传输,服务器和客户端需要对数据类型进行编解码。客户端需要将方法调用的数据编码以后传输给服务器,服务器接收到数据以后解码出来,然后调用真实的方法来处理。
对于Hadoop1.0, 他自己基于Java实现了一个Writable的序列化框架,但是只支持Java语言。Hadoop 2.0 引入支持多种序列化框架比如 ProtocolBuffer. 其实 Hadoop WritableObject 序列化框架实现如下:
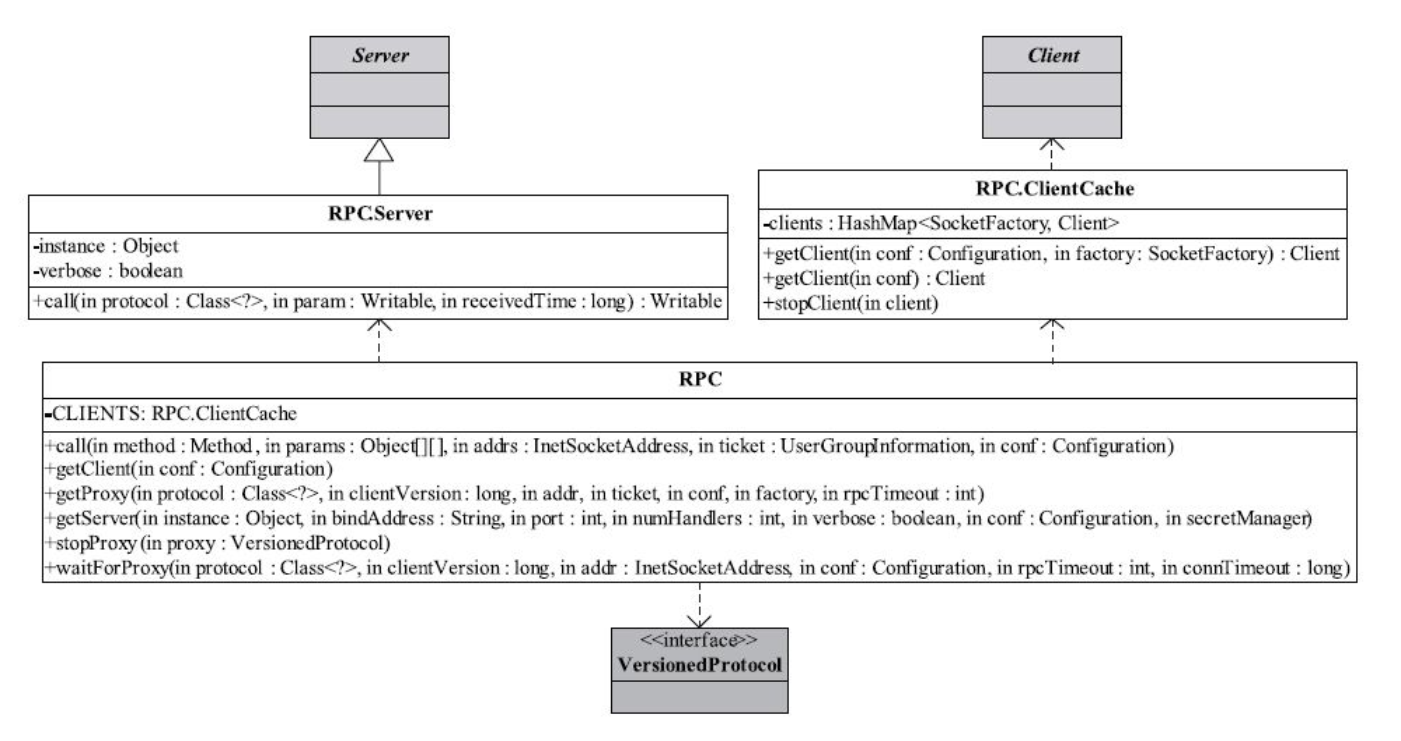
Hadoop RPC 的主要框架使用类
RPC 整个是一个工具类,提供 获取客户端代理Proxy 和 Server的方法。
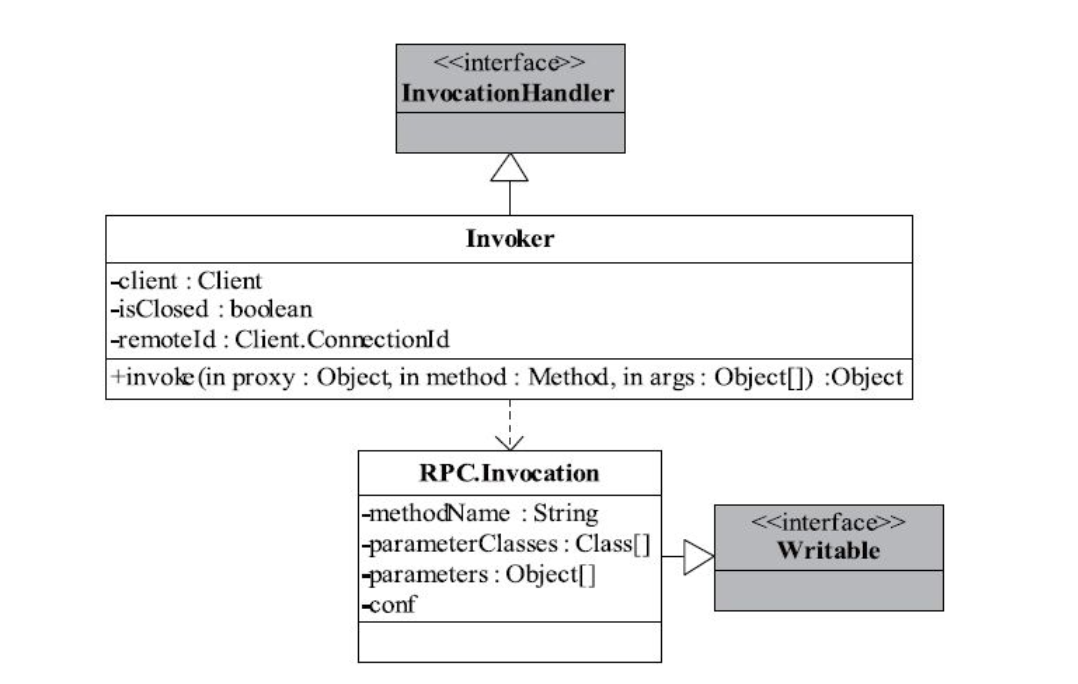
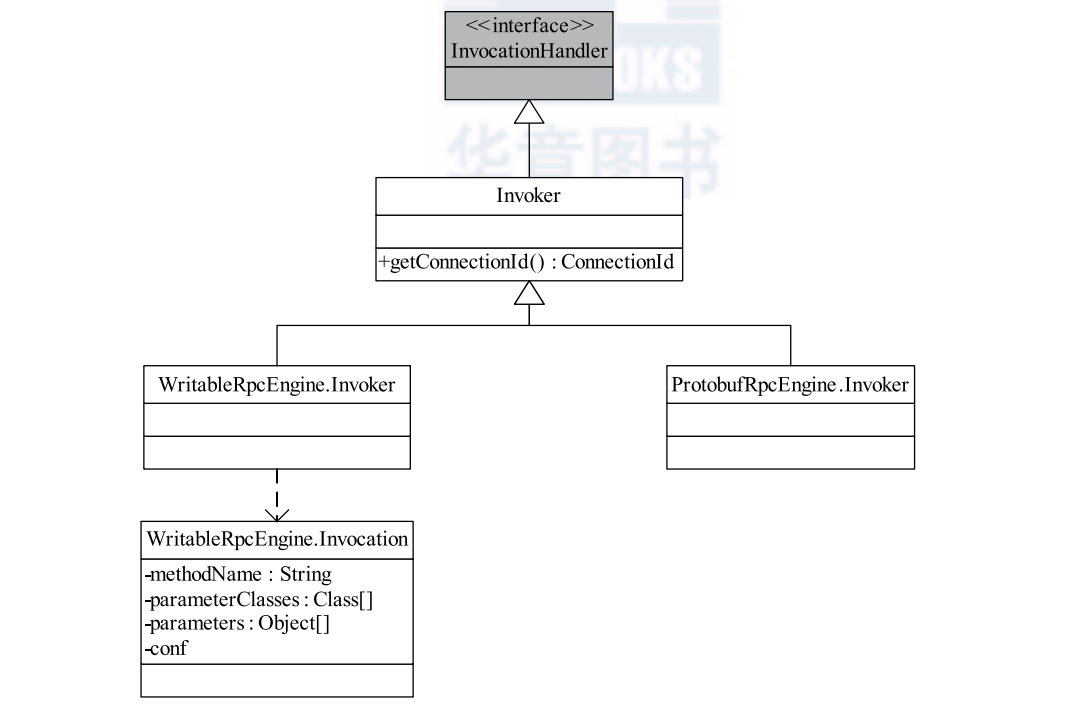
还有动态代理需要实现的 InvocationHandler 以及 RPC 调用的可序列化类 Invocation.
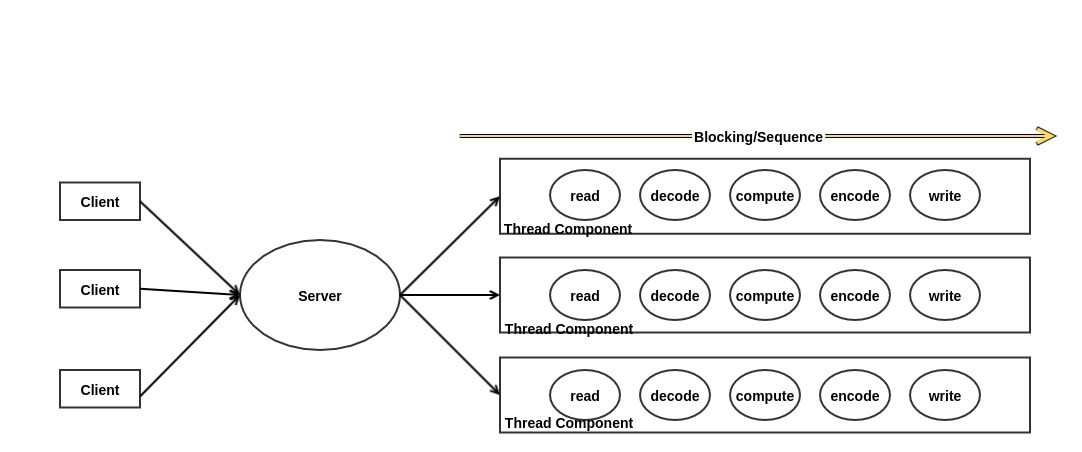
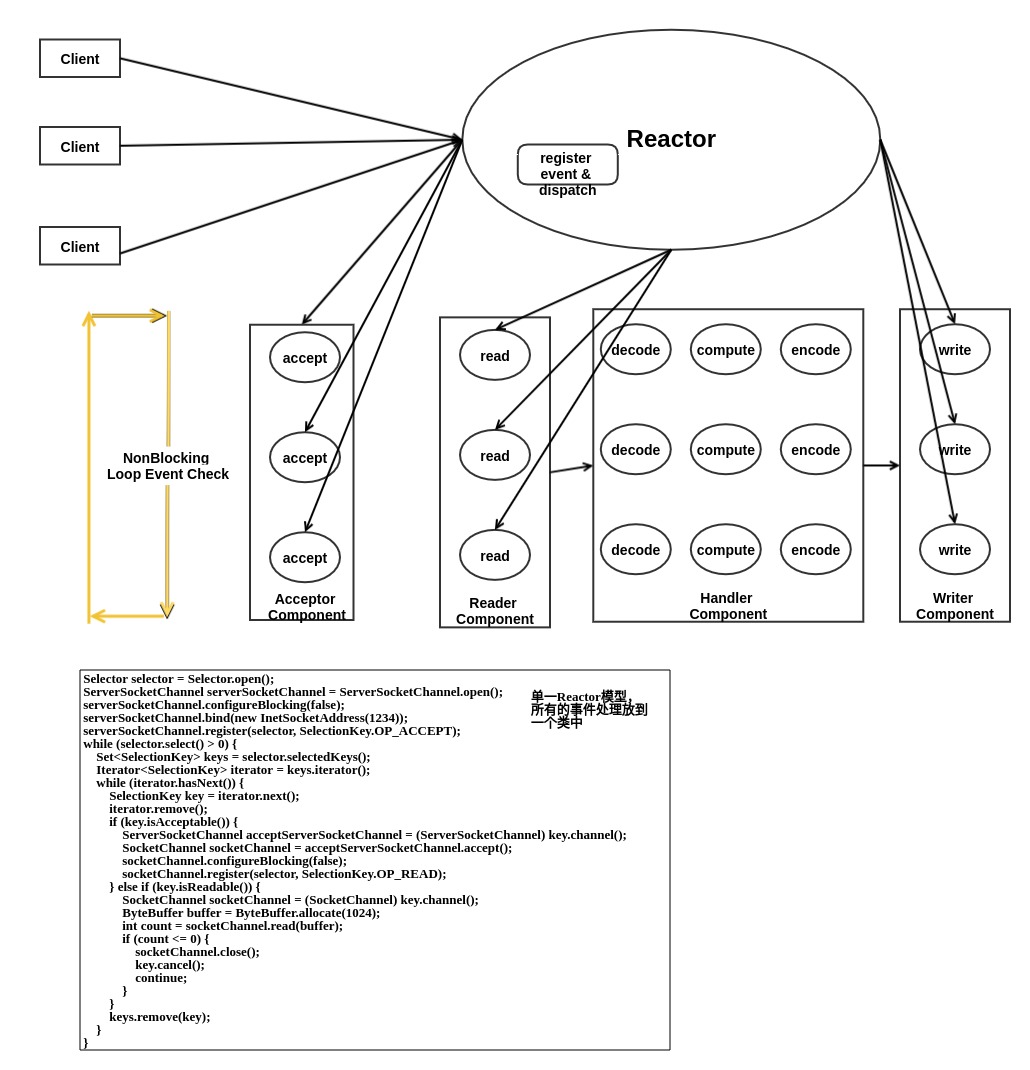
服务器 Reactor 模型
经典的并发模型是多线程以及线程池并发模型,线程并发模型采用的逻辑是每个线程处理一个连接,各个线程处理连接互不干扰,每个线程内部只需要按顺序处理事务数据的读入,计算,写回,可以看成是对所有事务的横向处理,比较符合人脑的逻辑,事务处理的逻辑抽象成一个执行组件(往往是一个线程),然后开启多线程并行执行,这样代码逻辑简单清晰,容易理解和编写,但是可能往往需要处理同步和锁的问题。多线程并发模型如下图所示:
举个例子,比如过年我们一家四口人为客人提供饺子,这里的例子不是很恰当,为了类比,这里假设客人们的饺子请求数据是慢慢到达的,比如先吃8个煎饺,再吃8个水饺等。并发的提出吃饺子的请求。为了加快处理速度,可以这样实现,包饺子分为制作饺子馅儿(饺子皮已经买好了),包装饺子,下锅烹饪,送给客人吃。如果我家里每个人都熟悉饺子制作的全部流程,而且资源很多(比如有多口锅,多个煤气灶,多份饺子馅儿原料),那么我家里四个人每个人负责的都是制作饺子的全部流程,让后并行的制作饺子,毫不冲突,客人可以单独给我们任何人提出饺子需求。但是往往现实是,只有一口锅,一个煤气灶,因此我家里每个人的包饺子全部流程的代码中就会产生用锅和煤气灶的冲突了,一个用完,另一个用,需要同步枷锁。这里家里四个人每个人负责的是一个客人的全部阶段,循环的是家里人谁空闲谁就可以做,我们四个人是并行的,但是每个客人的处理流程是串行的。
Reactor 是事件驱动并发模型,对于 Reactor 模型而言,实际上每个事务都可以最终抽象拆分成 读入,计算,写回 三个步骤的。Reactor 模型实际上是对每个 读入进行抽象成一个读组件,计算部分抽象成计算组件,写回部分抽象成写回组件,它是对事务的纵向的理解和拆分,比较违背大脑逻辑,代码不容易写出来,要想这样抽象代码,因为这里面涉及到上下文切换和保存现场,每个组件需要知道并发过来的这些请求,每一个到底执行到什么程度了,需要循环监听各个连接的读写事件。Reactor并发模型如下图所示:
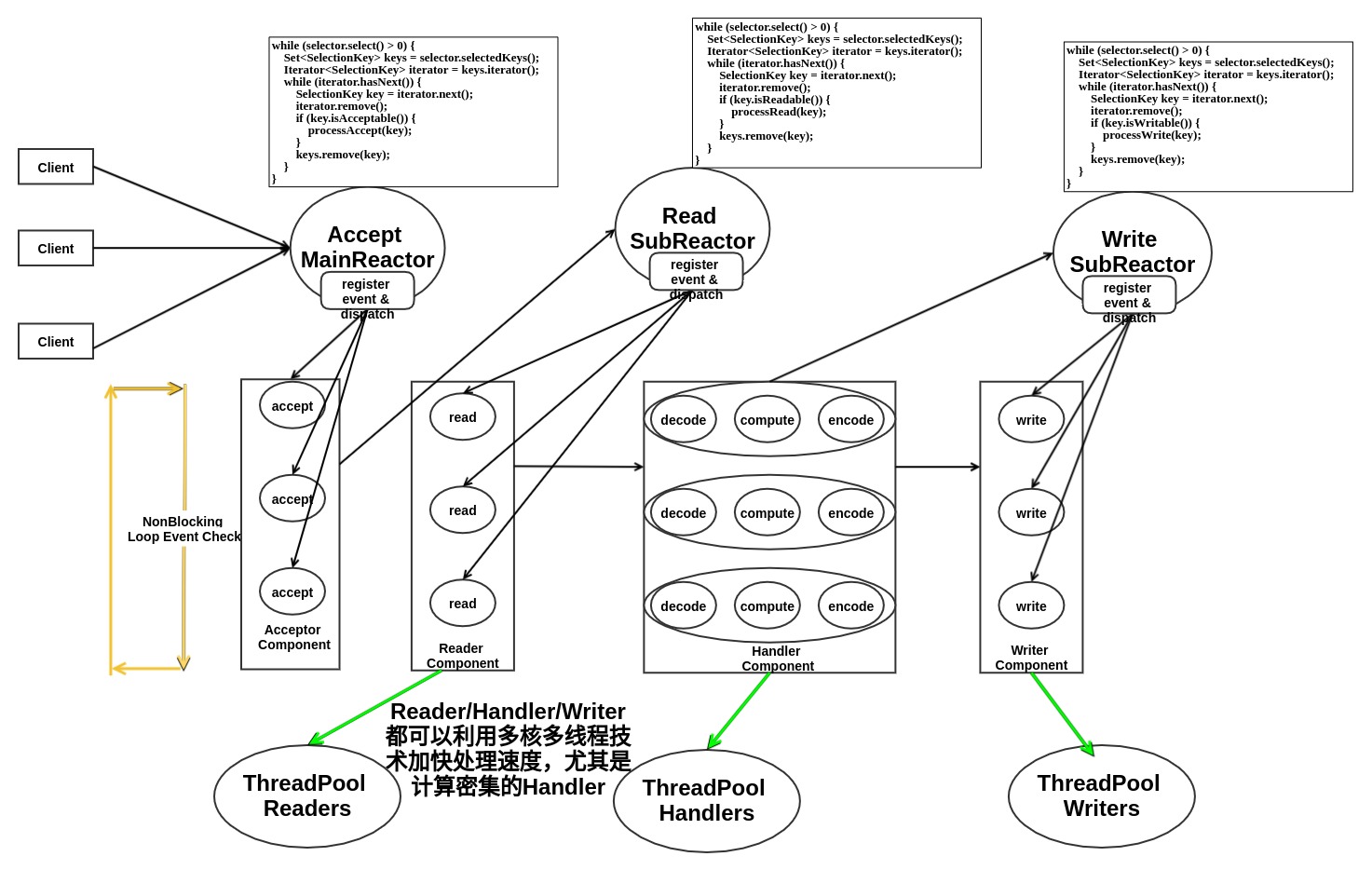
Reactor 其实可以有多个,形成多Reactor模型,每个Reactor只负责监听某个事件,并可以适当的利用多核处理加速, 下图是多Reactor模型。
还是制作饺子的例子,假设客人的饭量都不同,这里老爸专门负责做饺子馅,老妈负责包饺子,我负责烹饪饺子,姐姐负责送饺子,假设老爸负责制作饺子馅儿,老爸需要记住并发过来的每个客人的食量以及请求到达阶段,将并发来的客人饺子馅儿按顺序处理好,老妈需要包好饺子分门别类,按照客人装盘,我就按照到来的装盘饺子按顺序烹饪,姐姐最后分们别类的送出各个客人的饺子。这里基本上没有资源冲突,每个人负责某一个阶段。这里还会发生比如可能某些客人要吃的饺子很多,姐姐饺子送的太慢了,我的新客人的饺子快好了,但是她还没准备好,我只能把饺子放一边先记住,让后处理另一个客人的饺子,等我姐准备好了,我就给她我刚才记住的饺子,拿走送给客人吃。这里的每个人都负责的是多个客人请求的某一个阶段,循环监听的是客人某个阶段的事件,事件完成就可以通知下一个阶段的人了。每个阶段处理的时候是循环串行处理的,但是四个阶段是并行的(当然并不是某个客人的四个阶段并行了,而是总体来看多个客人的四个阶段并行了)。但实际上,每个阶段也是可以利用并行加速的,比如假设我会多重影分身且有多口锅,那么烹饪饺子是可以并行的,不一定是要串行。
其实 Reactor 利用了流水线的思想。流水线作业的思想无处不在,从计算机体系结构里的硬件处理器指令流水,Unix 系统软件的管道Pipeline哲学,到生活中生产线工厂,全部是流水线作业。整个社会就是巨大的流水线,各个专业的人相互合作,构成一个系统。而多线程模型只是其中的某个专业领域的多人竞争,也可以说是具有完全相同业务的同种公司之间在并行解决世界上相同问题。分工,协作和资源互斥基本上是并发技术的核心要素。
服务器Reactor模型能够实现,要借助操作系统的非阻塞IO和事件监听机制。因为我们看到 Reactor 模型的每个组件基本都在循环,如果你用的是阻塞IO,那循环岂不是会因为某个IO阻塞在哪里,永远也不执行了,那么其他有事件发生的IO就得不到处理了。
那么 Reactor 并发相比多线程并发有哪些优点。其实如果单独看这两种模型,不考虑资源限制的话,我更喜欢多线程模型,因为它更简单啊。但是,考虑资源等其他因素的时候,可能就不一样了。
可扩展性
对于并发数目只有几百的情况,每个线程处理一个连接是没问题的。但是对于百万并发连接的情况,多线程并发模型是无法扩展工作的。假设我们使用Java开发服务器,每个线程将会占用 320K ~ 1024K JVM 栈内存。那么 1,000,000 个线程就会占用 1 TB 内存。这还只是栈内存,不计算堆内存。并且线程虽然比进程轻量,但是操作系统创建线程还是有开销的。
为了降低线程数目,一般采用的是线程池模型,先固定开启多个线程(比如256个),连接请求放入队列中,由线程池中的线程取出来执行。但是这种设计有一个假设,就是假设连接是比较常规的短时连接。一旦突然所有的连接都变成长连接,那么所有线程就全部阻塞,然后线程池就会再次启动更多的线程来处理新连接,但是如果还是一样阻塞,那么服务器就会无法响应新连接了。由于线程数目和开销的限制,这种线程池方案也无法扩展到并发 1,000,000 长连接。
但是 Reactor 模型就没有线程数目的限制,因为它不会因为新的长连接开辟新线程。Reactor 中的连接线程可以利用非阻塞IO循环处理多个连接建立请求,即使是 1,000,000 个长连接,也只是需要轮训监听ACCEPT事件就可以了。最多是需要开启更多的 Reader/Sender/Handler线程而已,但是这个并不是和连接数线性相关的。因此,Reactor 模型具备更好的扩展性。
当然,Reactor 模型并不是就这么容易实现,由于引入多个连接循环处理的问题,就会出现消息读一半就去读其他连接了,这样需要保存现场,需要设计合理的消息存储结构和格式,防止用完内存,因为一个消息读出来需要申请多大的内存往往旧不知道了,因为可能每次只读一部分就切换去读取其他连接的消息了。消息格式设计有很多中,一般采用的是 TLV 格式(Type,Length,Value), 这样消息到来的时候先读到大小,你就知道需要多少内存了,更易于管理内存开销。
hadoop 1.0 RPC Client
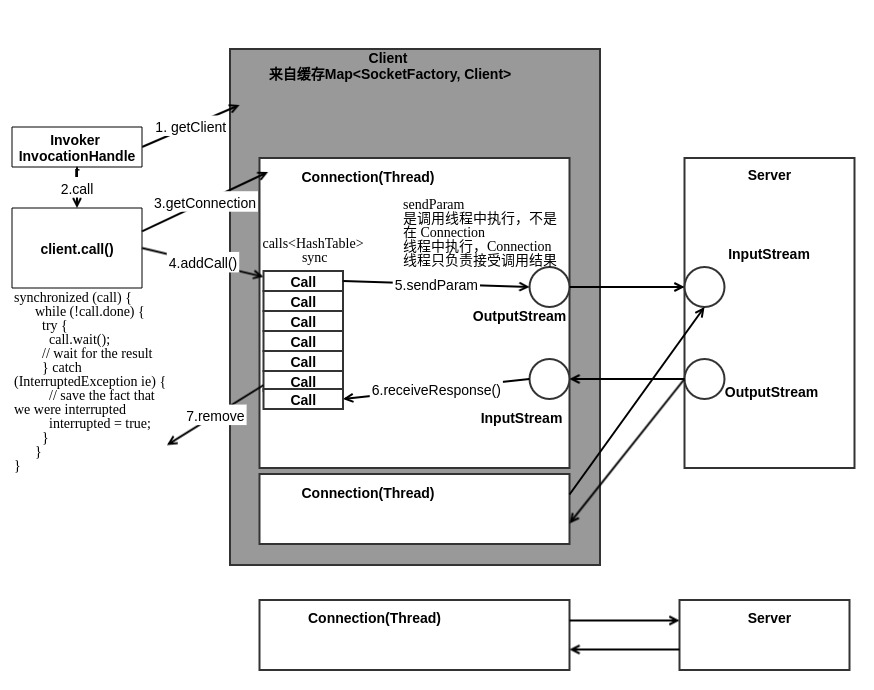
Call类: 该类封装了一个RPC请求, 它包含五个成员变量, 分别是唯一标识id、 函数调用信息param、 函数执行返回值value、 出错或者异常信息error和执行完成标识符done。 由于Hadoop RPC Server采用了异步方式处理客户端请求, 这使得远程过程调用的发生顺序与结果返回顺序无直接关系, 而Client端正是通过id识别不同的函数调用。 当客户端向服务器端发送请求时, 只需填充id和param两个变量, 而剩下的三个变量: value, error和done, 则由服务器端根据函数执行情况填充。
Connection类: Client与每个Server之间维护一个通信连接。 该连接相关的基本信息及操作被封装到Connection类中。他是一个线程类, 其中, 基本信息主要包括: 通信连接唯一标识(remoteId) , 与Server端通信的Socket(socket) , 网络输入数据流(in) , 网络输出数据流(out) , 保存RPC请求的哈希表(calls) 等; 操作则包括:
1. addCall——将一个Call对象添加到哈希表中;
2. sendParam——向服务器端发送RPC请求;
3. receiveResponse——从服务器端接收已经处理完成的RPC请求;
4. run——Connetion是一个线程类, 它的run方法调用了receiveResponse方法, 会一直等待接收RPC返回结果。
下图是客户端一次RPC调用的流程图:
hadoop 1.0 RPC Server
Server 的实现如下图所示, 采用了 Reactor 模型。
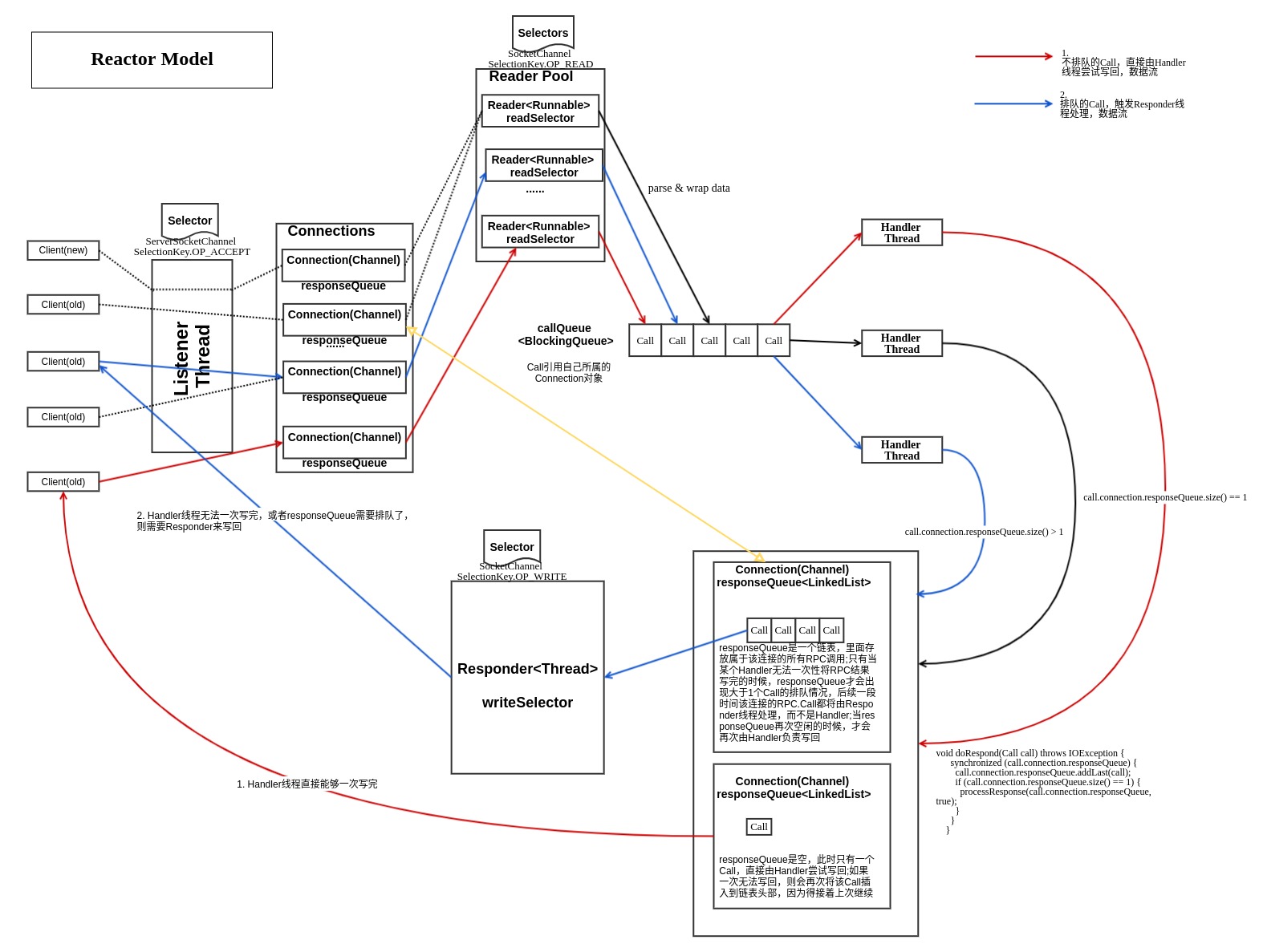
(1)接受请求
整个Server只有一个Listener线程, 统一负责监听来自客户端的连接请求。 一旦有新的请求到达, 它会采用轮询的方式从线程池中选择一个Reader线程进行处理。 而Reader线程可同时存在多个, 它们分别负责接收一部分客户端连接的RPC请求。 至于每个Reader线程负责哪些客户端连接, 完全由Listener决定。 当前Listener只是采用了简单的轮询分配机制。
Listener和Reader线程内部各自包含一个Selector对象, 分别用于监听SelectionKey.OP_ACCEPT和SelectionKey.OP_READ事件。 对于Listener线程, 主循环的实现体是监听是否有新的连接请求到达, 并采用轮询策略选择一个Reader线程处理新连接; 对于Reader线程, 主循环的实现体是监听( 它负责的那部分) 客户端连接中是否有新的RPC请求到达, 并将新的RPC请求封装成Call对象, 放到共享队列callQueue中。
(2) 处理请求
该阶段的主要任务是从共享队列callQueue中获取Call对象, 执行对应的函数调用, 并将结果返回给客户端, 这全部由Handler线程完成。Server端可同时存在多个Handler线程。 它们并行从共享队列中读取Call对象, 经执行对应的函数调用后, 将尝试着直接将结果返回给对应的客户端。 但考虑到某些函数调用返回的结果很大或者网络速度过慢, 可能难以将结果一次性发送到客户端, 此时Handler将尝试着将后续发送任务交给Responder线程。
(3) 返回结果
前面提到, 每个Handler线程执行完函数调用后, 会尝试着将执行结果返回给客户端, 但对于特殊情况, 比如函数调用返回的结果过大或者网络异常情况( 网速过慢) , 会将发送任务交给Responder线程。Server端仅存在一个Responder线程。 它的内部包含一个Selector对象, 用于监听SelectionKey.OP_WRITE事件。 当Handler没能够将结果一次性发送到客户端时, 会向该Selector对象注册SelectionKey.OP_WRITE事件, 进而由Responder线程采用异步方式继续发送未发送完成的结果。
Listener
Listener就是监听 ServerSocketChannel 的 ACCEPT 事件,不断的处理新连接的到来。Listener 和 Reader 之间是需要通过 Reader.adding 进行同步的。因为 Listener 在向 Reader 注册新的连接读事件的时候,是需要确保 Reader 中 readSelector.select() 不阻塞,且需要等待注册完成以后才可以开始循环监听。所有多线程操作 Selector.select() 和 SocketChannel.register(selector) 都需要这种同步。
public void run() { SERVER.set(Server.this);// ThreadLocal // 经典 Selector 循环事件监听模型 while (running) { SelectionKey key = null; try { selector.select(); Iterator<SelectionKey> iter = selector.selectedKeys().iterator(); while (iter.hasNext()) { key = iter.next(); iter.remove(); try { if (key.isValid()) { if (key.isAcceptable()) doAccept(key); } } catch (IOException e) { } key = null; } } //清除和停止各种资源和连接... } void doAccept(SelectionKey key) throws IOException, OutOfMemoryError { Connection c = null; ServerSocketChannel server = (ServerSocketChannel) key.channel(); SocketChannel channel; // 监听到 ACCEPT 事件以后,通过循环accept获取SocketChannel,可能多个新连接 while ((channel = server.accept()) != null) { channel.configureBlocking(false); channel.socket().setTcpNoDelay(tcpNoDelay); Reader reader = getReader(); //循环获取一个reader try { reader.startAdd();// 若reader在select中阻塞,唤醒select方法,并置Reader到wait状态 // 注册SocketChannel到reader.readSelector, 监听READ事件 SelectionKey readKey = reader.registerChannel(channel); c = new Connection(readKey, channel, System.currentTimeMillis()); readKey.attach(c); synchronized (connectionList) { connectionList.add(numConnections, c); numConnections++; } } finally { reader.finishAdd(); // 将Reader从wait状态唤醒 } } } void doRead(SelectionKey key) throws InterruptedException { int count = 0; Connection c = (Connection)key.attachment(); if (c == null) { return; } c.setLastContact(System.currentTimeMillis()); count = c.readAndProcess(); }
Reader
Reader 不止一个,可以由很多Reader构成的线程池,每个Reader只负责部分Connection的读事件监听和处理。主要是 RPC 连接开始时候的头认证,以及后续的 RPC Call 处理。Reader 需要和 Listener进行同步,因为在注册事件的时候, Selector.select() 必须被唤醒才可以。其次,在注册的过程中,Reader必须进入等待状态以等待注册完成。
public void run() { LOG.info("Starting SocketReader"); synchronized (this) { while (running) { SelectionKey key = null; readSelector.select(); // 被唤醒以后,需要等待注册事件完成,必须释放锁this, // 这样才能让其他线程调用registerChannel,并通过finishAdd唤醒等待或者超时 while (adding) { this.wait(1000); } // selector经典循环模式 Iterator<SelectionKey> iter = readSelector.selectedKeys().iterator(); while (iter.hasNext()) { key = iter.next(); iter.remove(); if (key.isValid()) { if (key.isReadable()) { doRead(key); } } key = null; } } } } /** * 让reader进入等待状态,该状态可以允许新连接注册到readSelector * 如果reader正在select()上阻塞,则立即唤醒返回,否则,select() * 的调用会立即返回,无论当前是否有read事件; * 该方法需要和finishAdd结合使用,用以唤醒reader从该等待状态退出 */ public void startAdd() { adding = true; readSelector.wakeup(); } public synchronized SelectionKey registerChannel(SocketChannel channel) throws IOException { return channel.register(readSelector, SelectionKey.OP_READ); } public synchronized void finishAdd() { adding = false; this.notify(); }
Handler
Handler属于 callQueue(callQueue 是并发包里的BlockingQueue) 的消费者,不断的取出 Call 调用真实的RPC函数进行计算并返回结果, Handler 可以说是Reactor模型中的逻辑计算模块(decode+compute+encode),不过这里 decode 模块被放入 Reader中了; Handler通常会通过调用 Responder.doRespond(Call) 尝试自己写回结果, 在 doRespond 逻辑里,对于responseQueue(不是FIFO,只是一个链表) 还有未处理call的情况,只是加入responseQueue,交给responder线程处理; 对于 responseQueue 只有一个当前Call的情况,则 Handler 会自己调用一次 Responder.processResponse() 在自己线程中尝试写回,如果一次无法全部写回的则会再次插入responseQueue队首,交给 Responder。
public void run() { SERVER.set(Server.this); ByteArrayOutputStream buf = new ByteArrayOutputStream(INITIAL_RESP_BUF_SIZE); while (running) { final Call call = callQueue.take(); // pop the queue; maybe blocked here Writable value = null; CurCall.set(call); // Make the call as the user via Subject.doAs, thus associating // the call with the Subject if (call.connection.user == null) { value = call(call.connection.protocol, call.param, call.timestamp); } else { ... } CurCall.set(null); synchronized (call.connection.responseQueue) { // setupResponse() needs to be sync'ed together with // responder.doResponse() since setupResponse may use // SASL to encrypt response data and SASL enforces // its own message ordering. setupResponse(buf, call, (error == null) ? Status.SUCCESS : Status.ERROR, value, errorClass, error); // Discard the large buf and reset it back to // smaller size to freeup heap if (buf.size() > maxRespSize) { buf = new ByteArrayOutputStream(INITIAL_RESP_BUF_SIZE); } responder.doRespond(call); } } }
Responder Thread
Responder 是一个单独的写线程,负责监听所有连接的写事件,并处理Handler无法一次性处理完成的Call以及后续因responseQueue.size()大于1造成的排队Call。和 Reader 中的模式相似,注册写监听事件之前,都需要先唤醒 selector.select(); 并且 Responder 需要和 Handler 进行同步,防止Handler在注册事件的时候,Responder还在进行事件监听,此时直接将 Responder 置入 waitPending 状态。
public void run() { SERVER.set(Server.this); long lastPurgeTime = 0; // last check for old calls. while (running) { try { waitPending(); // 一个Channel正在注册的时候,必须等待 writeSelector.select(PURGE_INTERVAL); Iterator<SelectionKey> iter = writeSelector.selectedKeys().iterator(); while (iter.hasNext()) { SelectionKey key = iter.next(); iter.remove(); if (key.isValid() && key.isWritable()) { doAsyncWrite(key); } } long now = System.currentTimeMillis(); if (now < lastPurgeTime + PURGE_INTERVAL) { continue; } lastPurgeTime = now; //长时间无法发送出去的Call,进行清除操作 ArrayList<Call> calls; // get the list of channels from list of keys. synchronized (writeSelector.keys()) { calls = new ArrayList<Call>(writeSelector.keys().size()); iter = writeSelector.keys().iterator(); while (iter.hasNext()) { SelectionKey key = iter.next(); Call call = (Call)key.attachment(); if (call != null && key.channel() == call.connection.channel) { calls.add(call); } } } for(Call call : calls) { doPurge(call, now); } } catch (OutOfMemoryError e) { // 这里不断的复制新Call,当由太多线程注册了事件的时候,新建数据量过大可能导致内存耗尽 // 睡眠1分钟,给其他线程一点时间处理掉相关call try { Thread.sleep(60000); } catch (Exception ie) {} } catch (Exception e) {} } } private void doAsyncWrite(SelectionKey key) throws IOException { Call call = (Call)key.attachment(); if (call == null) { return; } if (key.channel() != call.connection.channel) { throw new IOException("doAsyncWrite: bad channel"); } synchronized(call.connection.responseQueue) { if (processResponse(call.connection.responseQueue, false)) { try { key.interestOps(0); } catch (CancelledKeyException e) { /* The Listener/reader might have closed the socket. * We don't explicitly cancel the key, so not sure if this will * ever fire. * This warning could be removed. */ } } } } // Remove calls that have been pending in the responseQueue // for a long time. private void doPurge(Call call, long now) throws IOException { LinkedList<Call> responseQueue = call.connection.responseQueue; synchronized (responseQueue) { Iterator<Call> iter = responseQueue.listIterator(0); while (iter.hasNext()) { call = iter.next(); if (now > call.timestamp + PURGE_INTERVAL) { closeConnection(call.connection); break; } } } } private boolean processResponse(LinkedList<Call> responseQueue, boolean inHandler) throws IOException { boolean error = true; boolean done = false; // there is more data for this channel. int numElements = 0; Call call = null; try { synchronized (responseQueue) { // If there are no items for this channel, then we are done numElements = responseQueue.size(); if (numElements == 0) { error = false; return true; // no more data for this channel. } // Extract the first call call = responseQueue.removeFirst(); SocketChannel channel = call.connection.channel; // Send as much data as we can in the non-blocking fashion int numBytes = channelWrite(channel, call.response); if (numBytes < 0) { return true; } if (!call.response.hasRemaining()) { call.connection.decRpcCount(); if (numElements == 1) { // last call fully processes. done = true; // no more data for this channel. } else { done = false; // more calls pending to be sent. } } else { // 无法一次写完,则需要再次加入到表头,下次首先执行该Call的后面部分写操作 call.connection.responseQueue.addFirst(call); // 如果是在Handler线程中调用的,则需要进行同步, // 让Responder线程进入等待状态,并唤醒writeSelector注册channel if (inHandler) { // set the serve time when the response has to be sent later call.timestamp = System.currentTimeMillis(); incPending(); try { // 唤醒writeSelector, 这样 channel.register() 才能完成注册操作 writeSelector.wakeup(); channel.register(writeSelector, SelectionKey.OP_WRITE, call); } catch (ClosedChannelException e) { //Its ok. channel might be closed else where. done = true; } finally { decPending(); //唤醒Responder等待,此时Responder会继续执行 } } } error = false; // everything went off well } } finally { if (error && call != null) { done = true; // error. no more data for this channel. closeConnection(call.connection); } } return done; } // 由Handler线程调用 void doRespond(Call call) throws IOException { synchronized (call.connection.responseQueue) { call.connection.responseQueue.addLast(call); if (call.connection.responseQueue.size() == 1) { processResponse(call.connection.responseQueue, true); } } } private synchronized void incPending() { // call waiting to be enqueued. pending++; } private synchronized void decPending() { // call done enqueueing. pending--; notify(); } private synchronized void waitPending() throws InterruptedException { while (pending > 0) { wait(); } }
ObjectWritable 序列化实现
序列化基本就是 Java Object --encode--> bytes --decode--> Java Object. Hadoop实现的Java序列化工具很简单,就是通过将类名和对象实例(实现writable接口)通过字节流传输。
/** * A polymorphic Writable that writes an instance with it's class name. Handles * arrays, strings and primitive types without a Writable wrapper. */ public class ObjectWritable implements Writable { private Class declaredClass; private Object instance; private static final Map<String, Class<?>> PRIMITIVE_NAMES = new HashMap<String, Class<?>>(); static { PRIMITIVE_NAMES.put("boolean", Boolean.TYPE); PRIMITIVE_NAMES.put("byte", Byte.TYPE); PRIMITIVE_NAMES.put("char", Character.TYPE); PRIMITIVE_NAMES.put("short", Short.TYPE); PRIMITIVE_NAMES.put("int", Integer.TYPE); PRIMITIVE_NAMES.put("long", Long.TYPE); PRIMITIVE_NAMES.put("float", Float.TYPE); PRIMITIVE_NAMES.put("double", Double.TYPE); PRIMITIVE_NAMES.put("void", Void.TYPE); } private static class NullInstance implements Writable { private Class<?> declaredClass; public NullInstance() { ; } public NullInstance(Class declaredClass) { this.declaredClass = declaredClass; } public void readFields(DataInput in) throws IOException { String className = in.readUTF(); declaredClass = PRIMITIVE_NAMES.get(className); if (declaredClass == null) { try { declaredClass = Class.forName(className); } catch (ClassNotFoundException e) { throw new RuntimeException(e.toString()); } } } public void write(DataOutput out) throws IOException { out.writeUTF(declaredClass.getName()); } } public static void writeObject(DataOutput out, Object instance, Class declaredClass) throws IOException { if (instance == null) { // null instance = new NullInstance(declaredClass); declaredClass = Writable.class; } out.writeUTF(declaredClass.getName()); // always write declared if (declaredClass.isArray()) { // array int length = Array.getLength(instance); out.writeInt(length); for (int i = 0; i < length; i++) { writeObject(out, Array.get(instance, i), declaredClass.getComponentType()); } } else if (declaredClass == String.class) { // String out.writeUTF((String) instance); } else if (declaredClass.isPrimitive()) { // primitive type if (declaredClass == Boolean.TYPE) { // boolean out.writeBoolean(((Boolean) instance).booleanValue()); } else if (declaredClass == Character.TYPE) { // char out.writeChar(((Character) instance).charValue()); } else if (declaredClass == Byte.TYPE) { // byte out.writeByte(((Byte) instance).byteValue()); } else if (declaredClass == Short.TYPE) { // short out.writeShort(((Short) instance).shortValue()); } else if (declaredClass == Integer.TYPE) { // int out.writeInt(((Integer) instance).intValue()); } else if (declaredClass == Long.TYPE) { // long out.writeLong(((Long) instance).longValue()); } else if (declaredClass == Float.TYPE) { // float out.writeFloat(((Float) instance).floatValue()); } else if (declaredClass == Double.TYPE) { // double out.writeDouble(((Double) instance).doubleValue()); } else if (declaredClass == Void.TYPE) { // void } else { throw new IllegalArgumentException("Not a primitive: " + declaredClass); } } else if (declaredClass.isEnum()) { // enum out.writeUTF(((Enum) instance).name()); } else if (Writable.class.isAssignableFrom(declaredClass)) { // Writable out.writeUTF(instance.getClass().getName()); ((Writable) instance).write(out); } else { throw new IOException("Can't write: " + instance + " as " + declaredClass); } } public static Object readObject(DataInput in) throws IOException { return readObject(in, null); } public static Object readObject(DataInput in, ObjectWritable objectWritable) throws IOException { String className = in.readUTF(); Class<?> declaredClass = PRIMITIVE_NAMES.get(className); if (declaredClass == null) { try { declaredClass = Class.forName(className); } catch (ClassNotFoundException e) { throw new RuntimeException("readObject can't find class " + className, e); } } Object instance; if (declaredClass.isPrimitive()) { // primitive types if (declaredClass == Boolean.TYPE) { // boolean instance = Boolean.valueOf(in.readBoolean()); } else if (declaredClass == Character.TYPE) { // char instance = Character.valueOf(in.readChar()); } else if (declaredClass == Byte.TYPE) { // byte instance = Byte.valueOf(in.readByte()); } else if (declaredClass == Short.TYPE) { // short instance = Short.valueOf(in.readShort()); } else if (declaredClass == Integer.TYPE) { // int instance = Integer.valueOf(in.readInt()); } else if (declaredClass == Long.TYPE) { // long instance = Long.valueOf(in.readLong()); } else if (declaredClass == Float.TYPE) { // float instance = Float.valueOf(in.readFloat()); } else if (declaredClass == Double.TYPE) { // double instance = Double.valueOf(in.readDouble()); } else if (declaredClass == Void.TYPE) { // void instance = null; } else { throw new IllegalArgumentException("Not a primitive: " + declaredClass); } } else if (declaredClass.isArray()) { // array int length = in.readInt(); instance = Array.newInstance(declaredClass.getComponentType(), length); for (int i = 0; i < length; i++) { Array.set(instance, i, readObject(in)); } } else if (declaredClass == String.class) { // String instance = in.readUTF(); } else if (declaredClass.isEnum()) { // enum instance = Enum.valueOf((Class<? extends Enum>) declaredClass, in.readUTF()); } else { // Writable Class instanceClass = null; String str = ""; try { str = in.readUTF(); instanceClass = Class.forName(str); } catch (ClassNotFoundException e) { throw new RuntimeException("readObject can't find class " + str, e); } Writable writable = (Writable) newInstance(instanceClass); writable.readFields(in); instance = writable; if (instanceClass == NullInstance.class) { // null declaredClass = ((NullInstance) instance).declaredClass; instance = null; } } if (objectWritable != null) { // store values objectWritable.declaredClass = declaredClass; objectWritable.instance = instance; } return instance; } private static final Map<Class<?>, Constructor<?>> CONSTRUCTOR_CACHE = new ConcurrentHashMap<Class<?>, Constructor<?>>(); public static <T> T newInstance(Class<T> theClass) { T result; try { Constructor<T> meth = (Constructor<T>) CONSTRUCTOR_CACHE.get(theClass); if (meth == null) { meth = theClass.getDeclaredConstructor(); meth.setAccessible(true); CONSTRUCTOR_CACHE.put(theClass, meth); } result = meth.newInstance(); } catch (Exception e) { throw new RuntimeException(e); } return result; } }
ByteBuffer & Channel
Channel 和 Stream 一样可读可写。
- int read( ByteBuffer dst) throws IOException: 将当前Channel中的数据读取到ByteBuffer中。 在阻塞和非阻塞模式下, 该函数实现方式不同: 在非阻塞模式下, 遵从能读取多少数据就读取多少数据的原则, 总是立即返回结果; 而在阻塞模式下, 将尝试一直读取数据, 直到ByteBuffer被填满, 到达输入流末尾或者抛出异常。 该函数的返回值为实际读取的数据字节数。
- int write( ByteBuffer src) throws IOException: 将ByteBuffer中的数据写入Channel中。 与read函数类似, 在阻塞模式和非阻塞模式下, 该函数实现方式不同: 在非阻塞模式下, 遵从能输出多少数据就输出多少数据的原则, 总是立即返回结果; 在阻塞模式下, 会尝试着将所有数据写入Channel, 如果底层的网络缓冲区容纳不了这么多字节, 则会阻塞至可写入所有数据或者抛出异常。
当调用write方法将一个Heap Buffer中的数据写入某个Channel( 或者调用read方法将Channel中的数据读入一个Heap Buffer对象) 时, Sun Java底层实现中使用了Direct Buffer暂时对数据进行缓冲, 大体步骤为: JVM初始创建一个固定大小的Direct Buffer, 并将数据写入该Buffer, 如果Buffer大小不够, 则再创建一个更大的Direct Buffer, 并将之前的Direct Buffer中的内容复制到新的Direct Buffer中, 依此类推, 直到将数据全部写入。 很明显, 该过程涉及大量内存复制操作, 会明显降低性能。 此外, 由于Direct Buffer所占内存不会被马上释放, 因此会造成内存使用骤升。 为解决该问题,可将写入的数据分成固定大小( 比如8KB) 的chunk, 并以chunk为单位写入Direct Buffer.
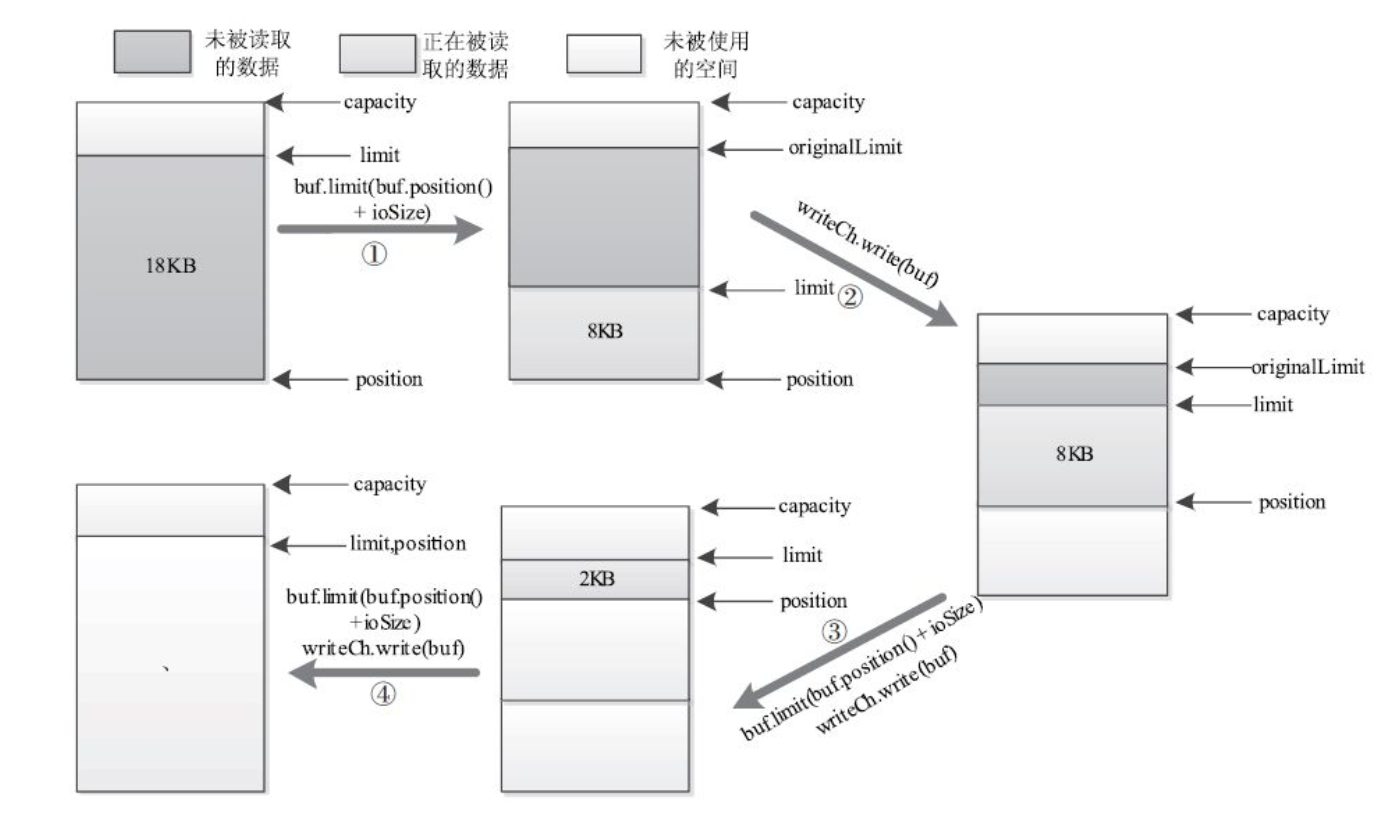
/** * When the read or write buffer size is larger than this limit, i/o will be * done in chunks of this size. Most RPC requests and responses would be * be smaller. */ private static int NIO_BUFFER_LIMIT = 8*1024; //should not be more than 64KB. /** * This is a wrapper around {@link WritableByteChannel#write(ByteBuffer)}. * If the amount of data is large, it writes to channel in smaller chunks. * This is to avoid jdk from creating many direct buffers as the size of * buffer increases. This also minimizes extra copies in NIO layer * as a result of multiple write operations required to write a large * buffer. * * @see WritableByteChannel#write(ByteBuffer) */ private int channelWrite(WritableByteChannel channel, ByteBuffer buffer) throws IOException { int count = (buffer.remaining() <= NIO_BUFFER_LIMIT) ? channel.write(buffer) : channelIO(null, channel, buffer); if (count > 0) { rpcMetrics.incrSentBytes(count); } return count; } /** * This is a wrapper around {@link ReadableByteChannel#read(ByteBuffer)}. * If the amount of data is large, it writes to channel in smaller chunks. * This is to avoid jdk from creating many direct buffers as the size of * ByteBuffer increases. There should not be any performance degredation. * * @see ReadableByteChannel#read(ByteBuffer) */ private int channelRead(ReadableByteChannel channel, ByteBuffer buffer) throws IOException { int count = (buffer.remaining() <= NIO_BUFFER_LIMIT) ? channel.read(buffer) : channelIO(channel, null, buffer); if (count > 0) { rpcMetrics.incrReceivedBytes(count); } return count; } private static int channelIO(ReadableByteChannel readCh, WritableByteChannel writeCh, ByteBuffer buf) throws IOException { int originalLimit = buf.limit(); int initialRemaining = buf.remaining(); int ret = 0; while (buf.remaining() > 0) { try { int ioSize = Math.min(buf.remaining(), NIO_BUFFER_LIMIT); buf.limit(buf.position() + ioSize); ret = (readCh == null) ? writeCh.write(buf) : readCh.read(buf); if (ret < ioSize) { break; } } finally { buf.limit(originalLimit); } } int nBytes = initialRemaining - buf.remaining(); return (nBytes > 0) ? nBytes : ret; } }
Hadoop RPC 2.0
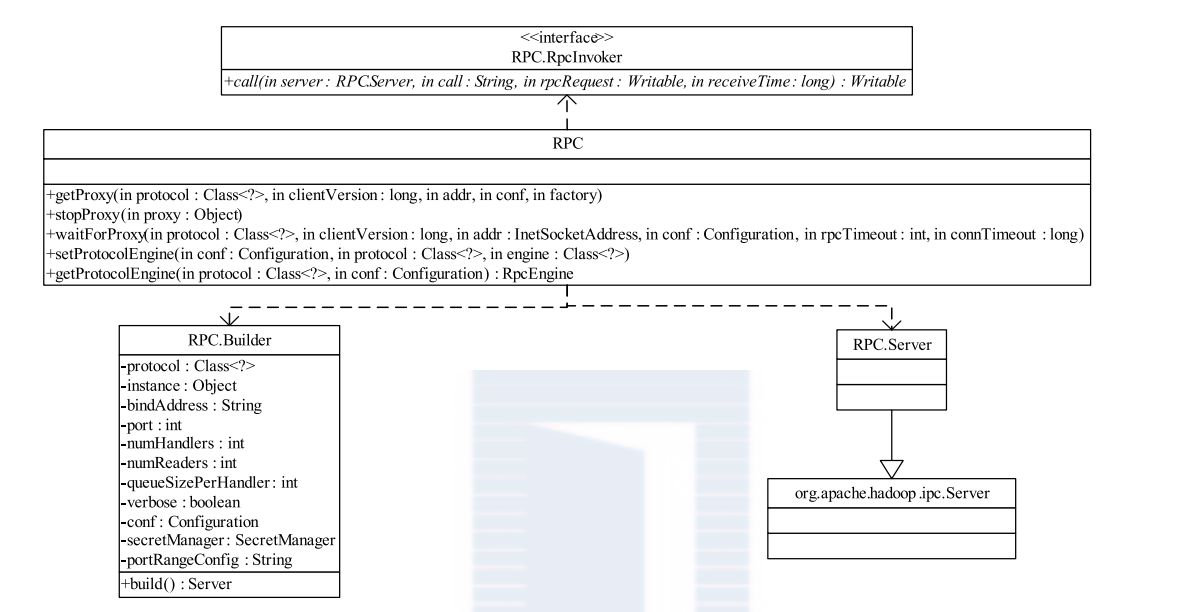
hadoop 2.0 为了支持集成更多 RPC 序列化引擎,对 1.0 进行了修改。Hadoop 2.0 RPC 代码更加抽象一些,原来的 RPC.invoker 类被剥离,然后由不同的 RPCEngine 实现各自的Invoker,RPC 主类只是一个空壳,真实的 proxy 都是 RPCEngine.getProxy() 通过动态代理产生的。 真实的 invoke 调用的时候不同的 RPCEngine 根据不同的序列化框架进行相应的序列化编码,但是只是改变了序列化方式,底层使用的 客户端-服务器模型 还是原来的 Reactor 模型代码,只是做了部分优化和修改。
下图是新 RPC 框架主类结构:
下图是实现RPCEngine 类图:
变化主要体现在一下几个方面:
1. RPC1.0 主类中默认的 InvocationHandler 其实默认是对 Writable 序列化方式的封装使用,也就是 Built-In 方式。Hadoop 2.0 将实现方式改成了支持各种基于不同序列化方式实现的 Invoker. 2.0 提供了 Writable(WritableRpcEngine)和 Protocol Buffers(ProtobufRpcEngine)两种,用户可通过调用RPC.setProtocolEngine() 修改采用的序列化方式。这种方式使得 RPC 使用框架代码更加抽象了。
```Java
public static void setProtocolEngine(Configuration conf,
Class<?> protocol, Class<?> engine) {
conf.setClass(ENGINE_PROP+"."+protocol.getName(), engine, RpcEngine.class);
}
// return the RpcEngine configured to handle a protocol static synchronized RpcEngine getProtocolEngine(Class<?> protocol, Configuration conf) { RpcEngine engine = PROTOCOL_ENGINES.get(protocol); if (engine == null) { Class<?> impl = conf.getClass(ENGINE_PROP+"."+protocol.getName(), WritableRpcEngine.class); engine = (RpcEngine)ReflectionUtils.newInstance(impl, conf); PROTOCOL_ENGINES.put(protocol, engine); } return engine; } public static <T> T getProxy(Class<T> protocol, long clientVersion, InetSocketAddress addr, UserGroupInformation ticket, Configuration conf, SocketFactory factory, int rpcTimeout) throws IOException { // ProtocolProxy 只是对真 Proxy 的封装,还需要再次调用 ProtocolProxy.getProxy() return getProtocolProxy(protocol, clientVersion, addr, ticket, conf, factory, rpcTimeout, null).getProxy(); } public static <T> ProtocolProxy<T> getProtocolProxy(Class<T> protocol, long clientVersion, InetSocketAddress addr, UserGroupInformation ticket, Configuration conf, SocketFactory factory, int rpcTimeout, RetryPolicy connectionRetryPolicy, AtomicBoolean fallbackToSimpleAuth) throws IOException { if (UserGroupInformation.isSecurityEnabled()) { SaslRpcServer.init(conf); } return getProtocolEngine(protocol, conf).getProxy(protocol, clientVersion, addr, ticket, conf, factory, rpcTimeout, connectionRetryPolicy, fallbackToSimpleAuth); }
```
- 为了支持识别不同的 RPC, Call 类加入了 RPC.rpcKind 变量。还加入了 traceSpan 变量用来支持服务跟踪。以及其他几个变量,并实现 Schedulable 接口。
public static class Call implements Schedulable { private final int callId; // the client's call id private final int retryCount; // the retry count of the call private final Writable rpcRequest; // Serialized Rpc request from client private final Connection connection; // connection to client private long timestamp; // time received when response is null // time served when response is not null private ByteBuffer rpcResponse; // the response for this call private AtomicInteger responseWaitCount = new AtomicInteger(1); private final RPC.RpcKind rpcKind; private final byte[] clientId; private final Span traceSpan; // the tracing span on the server side private Call(Call call) { this(call.callId, call.retryCount, call.rpcRequest, call.connection, call.rpcKind, call.clientId, call.traceSpan); } }
callQueue不再是默认的BlockingQueue,而是支持多种对Call的调度策略。有一个新的CallQueueManager类替代。-
Server 为了支持 Protocol Buffer 序列化,加入了解码 protobuf 的方法;
RpcRequestHeaderProto是protobuf 自动根据原型生成的代码,可以解码序列数据。同时客户端使用的 ProtobufRpcEngine.Invoker 也有自己的编码实现; 具体可以查看代码,需要了解 Protobuf 的使用方法,ProtobufRpcEngine 中实现了很多封装类。ProtobufRpcEngine.Server.call里面调用服务实例方法的方式也是通过 protobuf 发生了改变,不再是 WritableRpcEngine 简单使用反射调用。
```Java
private void processOneRpc(byte[] buf)
throws IOException, WrappedRpcServerException, InterruptedException {
int callId = -1;
int retry = RpcConstants.INVALID_RETRY_COUNT;
try {
final DataInputStream dis =
new DataInputStream(new ByteArrayInputStream(buf));
final RpcRequestHeaderProto header =
decodeProtobufFromStream(RpcRequestHeaderProto.newBuilder(), dis);
callId = header.getCallId();
retry = header.getRetryCount();
if (LOG.isDebugEnabled()) {
LOG.debug(" got #" + callId);
}
checkRpcHeaders(header);if (callId < 0) { // callIds typically used during connection setup processRpcOutOfBandRequest(header, dis); } else if (!connectionContextRead) { throw new WrappedRpcServerException( RpcErrorCodeProto.FATAL_INVALID_RPC_HEADER, "Connection context not established"); } else { processRpcRequest(header, dis); }
} catch (WrappedRpcServerException wrse) { // inform client of error
Throwable ioe = wrse.getCause();
final Call call = new Call(callId, retry, null, this);
setupResponse(authFailedResponse, call,
RpcStatusProto.FATAL, wrse.getRpcErrorCodeProto(), null,
ioe.getClass().getName(), ioe.getMessage());
call.sendResponse();
throw wrse;
}
}
privateT decodeProtobufFromStream(Builder builder,
DataInputStream dis) throws WrappedRpcServerException {
try {
builder.mergeDelimitedFrom(dis);
return (T)builder.build();
} catch (Exception ioe) {
Class<?> protoClass = builder.getDefaultInstanceForType().getClass();
throw new WrappedRpcServerException(
RpcErrorCodeProto.FATAL_DESERIALIZING_REQUEST,
"Error decoding " + protoClass.getSimpleName() + ": "+ ioe);
}
}
5. 引入更多流量控制机制,比如处理 RPC 的时候会根据队列负载情况通知客户端 backoffjava
private void processRpcRequest(RpcRequestHeaderProto header,
DataInputStream dis) throws WrappedRpcServerException,
InterruptedException {
Class<? extends Writable> rpcRequestClass =
getRpcRequestWrapper(header.getRpcKind());
if (rpcRequestClass == null) {
LOG.warn("Unknown rpc kind " + header.getRpcKind() +
" from client " + getHostAddress());
final String err = "Unknown rpc kind in rpc header" +
header.getRpcKind();
throw new WrappedRpcServerException(
RpcErrorCodeProto.FATAL_INVALID_RPC_HEADER, err);
}
Writable rpcRequest;
try { //Read the rpc request
rpcRequest = ReflectionUtils.newInstance(rpcRequestClass, conf);
rpcRequest.readFields(dis);
} catch (Throwable t) { // includes runtime exception from newInstance
LOG.warn("Unable to read call parameters for client " +
getHostAddress() + "on connection protocol " +
this.protocolName + " for rpcKind " + header.getRpcKind(), t);
String err = "IPC server unable to read call parameters: "+ t.getMessage();
throw new WrappedRpcServerException(
RpcErrorCodeProto.FATAL_DESERIALIZING_REQUEST, err);
}Span traceSpan = null;
if (header.hasTraceInfo()) {
// If the incoming RPC included tracing info, always continue the trace
TraceInfo parentSpan = new TraceInfo(header.getTraceInfo().getTraceId(),
header.getTraceInfo().getParentId());
traceSpan = Trace.startSpan(rpcRequest.toString(), parentSpan).detach();
}Call call = new Call(header.getCallId(), header.getRetryCount(),
rpcRequest, this, ProtoUtil.convert(header.getRpcKind()),
header.getClientId().toByteArray(), traceSpan);if (callQueue.isClientBackoffEnabled()) {
// if RPC queue is full, we will ask the RPC client to back off by
// throwing RetriableException. Whether RPC client will honor
// RetriableException and retry depends on client ipc retry policy.
// For example, FailoverOnNetworkExceptionRetry handles
// RetriableException.
queueRequestOrAskClientToBackOff(call);
} else {
callQueue.put(call); // queue the call; maybe blocked here
}
incRpcCount(); // Increment the rpc count
}private void queueRequestOrAskClientToBackOff(Call call)
throws WrappedRpcServerException, InterruptedException {
// If rpc queue is full, we will ask the client to back off.
boolean isCallQueued = callQueue.offer(call);
if (!isCallQueued) {
rpcMetrics.incrClientBackoff();
RetriableException retriableException =
new RetriableException("Server is too busy.");
throw new WrappedRpcServerException(
RpcErrorCodeProto.ERROR_RPC_SERVER, retriableException);
}
}
```
YarnRPC
Hadoop 2.0 开始引入资源管理框架 Yarn, 由于 mapred v2.0 建立再 Yarn 之上,因此 Yarn 也提供了 RPC,Yarn 的RPC主类框架代码则更加抽象。采用了工厂模式和单列模式。 Yarn 2.0 其实利用了 Hadoop 2.0 的 RPC 主类,默认采用了 Hadoop RPC 的底层通讯模型。下图是 Hadoop2.0 RPC 相关类图:
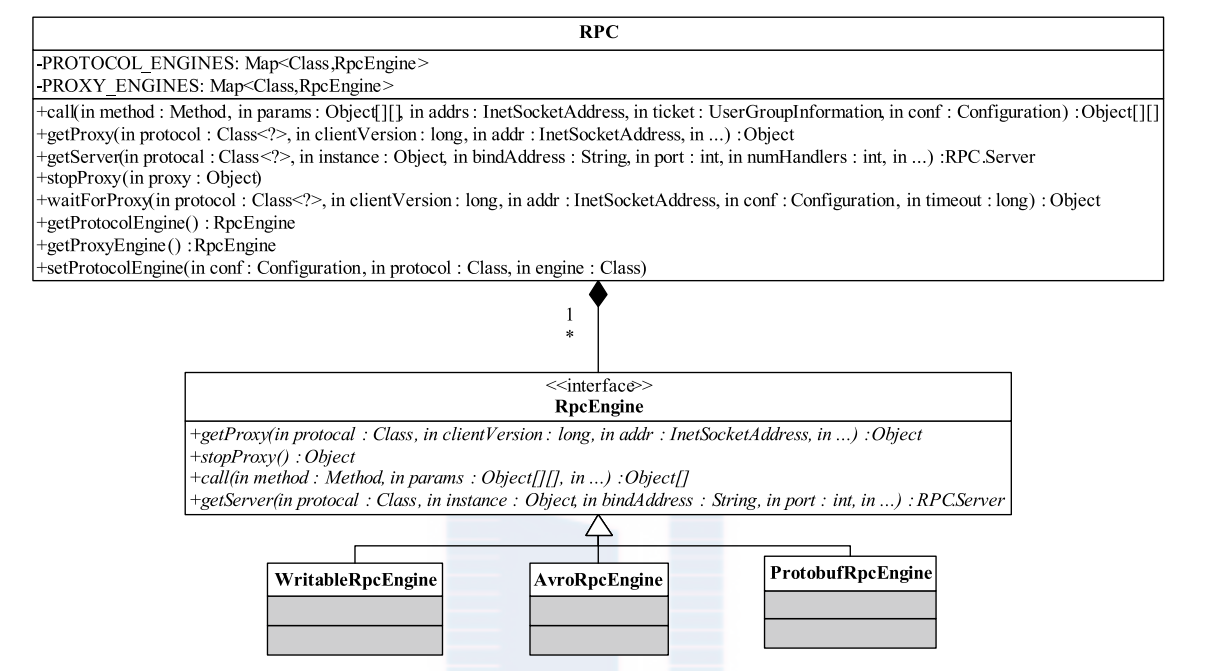
用户可通过配置参数 rpc.engine.{protocol} 以指定协议 {protocol} 采用的序列化方式。
下图是 YarnRPC 相关类图,YarnRPC 是一个抽象类, 实际的实现由参数 yarn.ipc.rpc.class 指定, 默认值是 org.apache.hadoop.yarn.ipc.HadoopYarnProtoRPC。 HadoopYarnProtoRPC 通过 RPC工厂生成器RpcFactoryProvider 生成客户端工厂(由参数 yarn.ipc.client.factory.class 指定,默认值是 org.apache.hadoop.yarn.factories.impl.pb.RpcClientFactoryPBImpl) 和服务端工厂(由参数yarn.ipc.server.factory.class 指定, 默认值是 org.apache.hadoop.yarn.factories.impl.pb.RpcServerFactoryPBImpl), 以根据通信协议的 Protocol Buffers 定义生成客户端对象和服务器对象。 可以看到 YarnRPC 的底层实现套用了 HadoopRPC 的 Client 和 Server类.
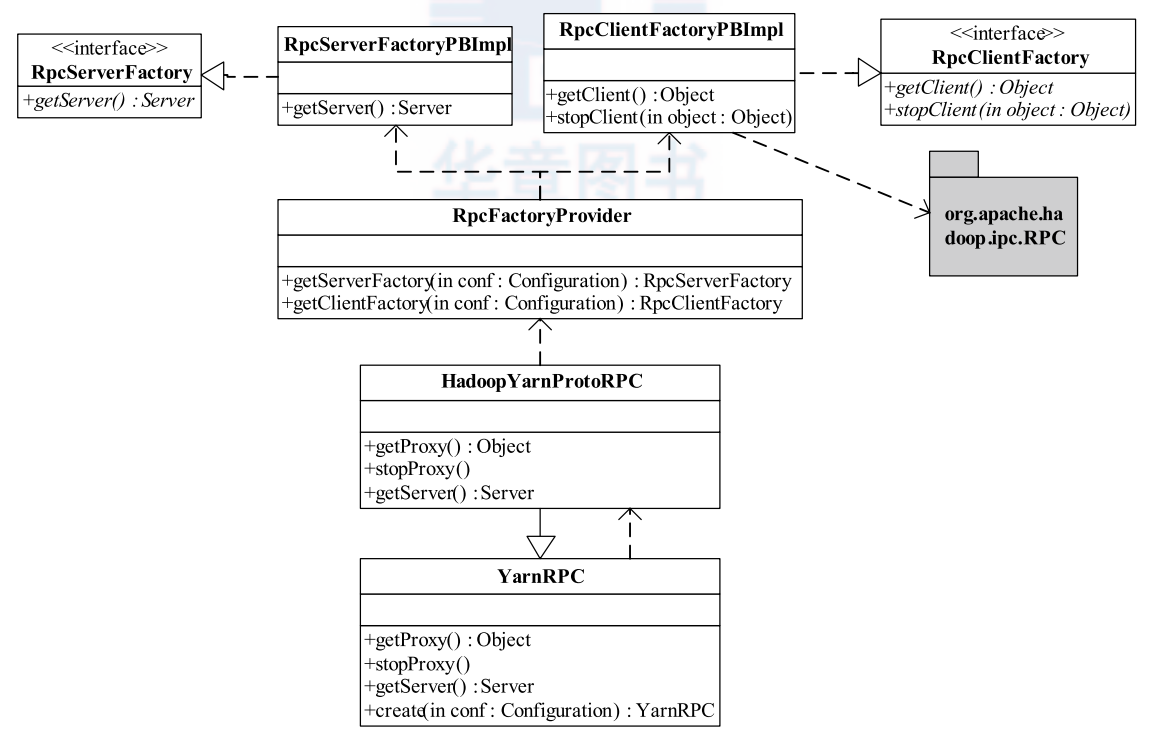
RpcClientFactoryPBImpl 通过实现某个协议客户端的类的类名加载该类,比如 ContainerManagementProtocolPBClientImpl, 其实最后该客户端类还是通过 Hadoop RPC 的 Client 类来通讯。
// RpcClientFactoryPBImpl public Object getClient(Class<?> protocol, long clientVersion, InetSocketAddress addr, Configuration conf) { Constructor<?> constructor = cache.get(protocol); if (constructor == null) { Class<?> pbClazz = null; pbClazz = localConf.getClassByName(getPBImplClassName(protocol)); constructor = pbClazz.getConstructor(Long.TYPE, InetSocketAddress.class, Configuration.class); constructor.setAccessible(true); cache.putIfAbsent(protocol, constructor); } Object retObject = constructor.newInstance(clientVersion, addr, conf); } // ContainerManagementProtocolPBClientImpl public ContainerManagementProtocolPBClientImpl(long clientVersion, InetSocketAddress addr, Configuration conf) throws IOException { RPC.setProtocolEngine(conf, ContainerManagementProtocolPB.class, ProtobufRpcEngine.class); UserGroupInformation ugi = UserGroupInformation.getCurrentUser(); int expireIntvl = conf.getInt(NM_COMMAND_TIMEOUT, DEFAULT_COMMAND_TIMEOUT); proxy = (ContainerManagementProtocolPB) RPC.getProxy(ContainerManagementProtocolPB.class, clientVersion, addr, ugi, conf, NetUtils.getDefaultSocketFactory(conf), expireIntvl); }
服务端 RPCServerFactoryImpl 类也是一样,利用了 Hadoop RPC 的 Server.
// RPCServerFactoryImpl private Server createServer(Class<?> pbProtocol, InetSocketAddress addr, Configuration conf, SecretManager<? extends TokenIdentifier> secretManager, int numHandlers, BlockingService blockingService, String portRangeConfig) throws IOException { RPC.setProtocolEngine(conf, pbProtocol, ProtobufRpcEngine.class); RPC.Server server = new RPC.Builder(conf).setProtocol(pbProtocol) .setInstance(blockingService).setBindAddress(addr.getHostName()) .setPort(addr.getPort()).setNumHandlers(numHandlers).setVerbose(false) .setSecretManager(secretManager).setPortRangeConfig(portRangeConfig) .build(); LOG.info("Adding protocol "+pbProtocol.getCanonicalName()+" to the server"); server.addProtocol(RPC.RpcKind.RPC_PROTOCOL_BUFFER, pbProtocol, blockingService); return server; }
Yarn 代码组织结构非常讲究,比如关于协议接口和实现等代码组织,有一定的规则。
1. RpcClientFactoryPBImpl : 根据通信协议接口(实际上就是一个 Java interface)及 Protocol Buffers 定义͵ 构造 RPC 客户端句柄, 但它对通信协议的存放位置和类名命有一定要求。假设通信协议 接口 Xxx 所在 Java 包名为XxxPackage, 则客户端实现代码必须位于Java包 XxxPackage.impl.pb.client 中(在接口包名后面增加.impl.pb.client), 且实现类名为 PBClientImplXxx(在接口名前面增加前缀PBClientImpl).
RpcServerFactoryPBImpl: 根据通信协议接口(实际上是一个 Java interface)及 Protocol Buffers 定͵ 构造 RPC 服务器句柄(该句柄将会调用 RPC.Server类),和客户端一样。假设通讯协议接口Xxx所在 Java 包名为XxxPackage, 则服务端实现代码必须位于 Java 包XxxPackage.impl.pb.server中(在接口包名后面增加.impl.pb.server), 且实现类名为PBServiceImplXxx(在接口名前面增加前缀PBServiceImpl)。
Hadoop YARN 已将 Protocol Buffers 作为默认的序列化机制(而不是 Hadoop 自带的 Writable), 这带来的好处主要表现在以下几个方面:

