伪共享和内存可见性(False Sharing 和 Memory Visibility)
伪共享
现在CPU的多核和多级缓存cache的特性,缓存系统往往是一行(cache line) 为基本单位(而不是单个字节或者变量)进行缓存的,当多线程修改相互独立的变量时,如果变量共享了同一个缓存行,就会无意的影响彼此的性能。
现代CPU为了cache数据的一致性,通过MESI协议来协调CPU核心的数据同步。
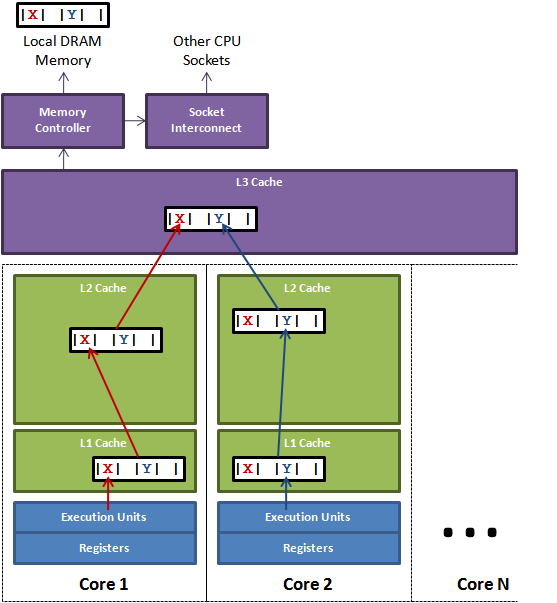
数据X、Y、Z被加载到同一Cache Line中,线程A在Core1修改X,线程B在Core2上修改Y。根据MESI,假设是Core1是第一个发起操作的CPU核,Core1上的L1 Cache Line由S(共享)状态变成M(修改,脏数据)状态,然后告知其他的CPU核,图例则是Core2,引用同一地址的Cache Line已经无效了;当Core2发起写操作时,首先导致Core1将X写回主存,Cache Line状态由M变为I(无效),而后才是Core2从主存重新读取该地址内容,Cache Line状态由I变成E(独占),最后进行修改Y操作, Cache Line从E变成M。
可见多个线程操作在同一Cache Line上的不同数据,相互竞争同一Cache Line,导致线程彼此牵制影响,变成了串行程序,降低了并发性。
Cache Line 现在X86-64 一般是64个字节一行。我们可以对变量进行补齐操作,以此来避免伪共享。
static class BadPopularObject { public volatile long usefulVal; } static class GoodPopularObject { public volatile long usefulVal; public volatile long t1, t2, t3, t4, t5, t6, t7; }
但是 Java 编译器优化的时候,会删除无效变量(就是那些只声明但是没有使用过的变量)。为了防止删除,我们可以在代码中多加一些函数,使用这些填充变量。
static class GoodPopularObject { public volatile long usefulVal; public volatile long t1, t2, t3, t4, t5, t6, t7; public long preventOptimization() { return t1 + t2 + t3 + t4 + t5 + t6 + t7; } }
上述的解决方法非常naive, 非常不方便。于是 Java 8 在 JEP 142: Reduce Cache Contention on Specified Fields引入了一种注解 @Contended 来防止伪共享。这个注解其实也是填充需要防止伪共享的变量。JVM会分配 128 bytes 即两个cache line而不是一个,原因是 CPU 体系结构中的指令数据预取操作(instruction prefetcher)。
static class SomePopularObject { @sun.misc.Contended public volatile long usefulVal; public volatile long anotherVal; }
下面测试一下伪共享的在多线程中的性能损失。
static class PaddingAtomicLong extends AtomicLong { public volatile long t1, t2, t3, t4, t5, t6, t7; public long preventOptimization() { return t1 + t2 + t3 + t4 + t5 + t6 + t7; } } static class FSTest implements Runnable { public final static int NUM_THREADS = 4; public final static long ITERATIONS = 100L * 1000L * 1000L; public static AtomicLong[] longs = new AtomicLong[NUM_THREADS]; public final int index; static { for (int i = 0; i < NUM_THREADS; i++) { longs[i] = new AtomicLong(); } } public FSTest(int index) { this.index = index; } public void run() { long i = ITERATIONS + 1; while (i-- > 0) { longs[index].set(i); } } public static void runTest() { Thread[] ts = new Thread[FSTest.NUM_THREADS]; for (int i = 0; i < FSTest.NUM_THREADS; i++) { FSTest fs = new FSTest(i); ts[i] = new Thread(fs); ts[i].start(); } for (Thread t : ts) { try { t.join(); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } } static class NFSTest implements Runnable { public final static int NUM_THREADS = 4; public final static long ITERATIONS = 100L * 1000L * 1000L; public static PaddingAtomicLong[] longs = new PaddingAtomicLong[NUM_THREADS]; public final int index; static { for (int i = 0; i < NUM_THREADS; i++) { longs[i] = new PaddingAtomicLong(); } } public NFSTest(int index) { this.index = index; } public void run() { long i = ITERATIONS + 1; while (i-- > 0) { longs[index].set(i); } } public static void runTest() { Thread[] ts = new Thread[NFSTest.NUM_THREADS]; for (int i = 0; i < NFSTest.NUM_THREADS; i++) { NFSTest nfs = new NFSTest(i); ts[i] = new Thread(nfs); ts[i].start(); } for (Thread t : ts) { try { t.join(); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } } public static void main(String[] args) { long start = System.nanoTime(); FSTest.runTest(); System.out.println(System.nanoTime() - start); start = System.nanoTime(); NFSTest.runTest(); System.out.println(System.nanoTime() - start); } \\8287659690 \\939645571
基本上伪共享会损失是10倍的性能。
多核CPU Volatile解决数据可见性 和 分布式数据一致性
最近突然发现,体系结构中 CPU 缓存数据可见性 和 分布式系统中数据一致性有相似之处,遂记录之。在分布式系统中,我们希望多个客户端访问数据的时候,看到的数据是一致的,比如 Zookeeper 中的数据,需要在多台机器同步,但是客户端看到的就是一份而已,当某个客户端对该数据做出修改,另外客户端是立即可见的(Zookeeper 采用的是强一致性)。
这就好比多线程共享同一份内存数据,线程看到的就是同一份而已,但其实多核都有缓存副本数据。多核CPU中,多线程在自己的 cache 中修改了数据,其他线程是无法立即看到的,Java 中为了保证数据的更改立即可见,就引入 volatile 关键字,就是数据的读取和写入不经过缓存,直接从主存进行读写。
由于 Zookeeper 需要保证数据在多个机器上一致,因此对于一个写请求,必须要把数据同步完成才可以返回,继而继续处理后续的请求。我们知道,Zookeeper 客户端取数据是可以连接到任意一个客户端进行的,但是如何才能保证读和写的原子互斥呢? 即当一个写请求发给一台机器,而一个读请求会发给另一台机器,这个时候,显然读写是会相互扰乱的,可能写还没完,读就开始了。
Zookeeper 是如何做到在一个写请求执行完成之后,读请求才开始的呢? 其实方法很简单,我们必须要让后续的读者或者写者知道,现在还有人在写呢? 因此需要一个统一的仲裁机构,这个机构就是我们所谓的 leader。 其实 Zookeeper 把所有的请求都先转发给 leader 了, 有了统一的仲裁机构,我们就可以知道读写的先后,比如时间或者编号等,然后保证读写的原子执行。
在保证了读写的原子执行以后,我们就来讨论 写 到什么时候才可以 读 的问题。

